Abstrak
Potensi interatomik pembelajaran mesin (MLIP) adalah teknik baru yang telah membantu mencapai simulasi dinamika molekuler dengan keseimbangan yang belum pernah terjadi sebelumnya antara efisiensi dan akurasi. Baru-baru ini, kumpulan literatur MLIP telah berkembang pesat, yang mendorong kebutuhan untuk memproses informasi yang relevan secara otomatis agar para peneliti dapat memahami dan memanfaatkannya. Pengenalan entitas bernama (NER), teknik pemrosesan bahasa alami yang mengidentifikasi dan mengkategorikan informasi dari teks, dapat membantu meringkas pendekatan dan temuan utama dari makalah yang relevan. Dalam karya ini, kami mengembangkan model NER untuk literatur MLIP dengan menyempurnakan model bahasa yang telah dilatih sebelumnya. Untuk menyederhanakan anotasi teks, kami membangun aplikasi web yang mudah digunakan untuk anotasi dan pemeriksaan akhir, yang terintegrasi dengan mulus ke dalam prosedur pelatihan. Model kami dapat mengidentifikasi entitas teknis dengan skor F1 sebesar 0,8 untuk abstrak makalah MLIP baru hanya dengan menggunakan 60 abstrak makalah pelatihan dan hingga 0,75 untuk teks ilmiah pada berbagai topik. Khususnya, beberapa “kesalahan” dalam prediksi sebenarnya merupakan keputusan yang wajar, yang menunjukkan kemampuan model melampaui apa yang ditunjukkan oleh metrik kinerja. Karya ini menunjukkan kemampuan linguistik pendekatan NER dalam memproses informasi tekstual dari domain ilmiah tertentu dan memiliki potensi untuk mempercepat penelitian material menggunakan model bahasa dan berkontribusi pada alur kerja yang berpusat pada pengguna.
1 Pendahuluan
Potensial interatomik (IP) adalah fungsi yang menghitung energi potensial suatu sistem atom yang diberikan posisinya, yang mengatur bagaimana partikel berinteraksi dalam simulasi dinamika molekuler (MD) [ 1 ]. IP berbasis fisika klasik, meskipun sederhana dan mudah ditafsirkan, terbukti tidak akurat dalam pemodelan fenomena fisika/kimia yang kompleks seperti bentang energi bebas molekul gas dalam kerangka logam-organik [ 2 ] dan perilaku mekanis berbagai material 2D [ 3 ]. Akurasi yang dibutuhkan dapat dicapai dengan simulasi kimia kuantum seperti teori fungsi kerapatan (DFT). Namun, biaya komputasinya mahal saat menghitung lintasan panjang atau sistem besar. Baru-baru ini, potensi interatomik pembelajaran mesin (MLIP) telah muncul sebagai solusi inovatif untuk dilema akurasi-efisiensi [ 4 ]. Prinsip kerja MLIP adalah mempelajari interaksi antara atom dari data referensi akurat yang biasanya dari DFT. Setelah pembelajaran, MLIP dapat dimasukkan ke dalam kerangka MD klasik seperti LAMMPS [ 5 ]. Dengan kemajuan teknik ML umum dan alat komputasi, berbagai jenis MLIP (MLIP berbasis lokal seperti DeePMD [ 6 ], SNAP [ 7 ], dan MLIP berbasis grafik seperti NequIP [ 8 ], MACE [ 9 ], misalnya,) telah diusulkan untuk memodelkan sistem material yang berbeda [ 10 ]. Literatur MLIP berkembang pesat, yang telah mendorong kebutuhan untuk memproses informasi relevan secara otomatis agar peneliti dapat memahami dan memanfaatkannya.
Model bahasa besar (LLM), yang terkenal seperti ChatGPT dan Llama, telah melampaui peran aslinya sebagai chatbot dan telah merevolusi lanskap penelitian seperti ilmu material dan kimia. Misalnya, LLM telah digunakan dalam penemuan material [ 11 ], laboratorium self-driving [ 12 ], dan ekstraksi informasi [ 13 ]. Meskipun keberhasilan ini, LLM terbukti rentan terhadap halusinasi [ 14 ], terutama untuk subjek ilmiah dan khusus seperti MLIP, di mana LLM domain luas tidak mampu menangkap kosakata khusus dan nuansa kontekstual yang penting untuk topik penelitian. Menyempurnakan LLM yang telah dilatih sebelumnya dengan data relevan yang dikurasi dari sumber yang dapat diandalkan seperti makalah penelitian domain dan anotasi ahli dapat membantu mengurangi hal ini. Untuk tugas ekstraksi pengetahuan, satu teknik pemrosesan bahasa alami (NLP) umum dinamai pengenalan entitas (NER), sebuah metode untuk mendeteksi entitas dalam teks tidak terstruktur dan mengkategorikannya ke dalam kategori yang telah ditentukan sebelumnya, yang, pada intinya, melakukan klasifikasi multikelas. NER memiliki beberapa aplikasi penting dalam penelitian dan sains seperti ekstraksi informasi,[ 15 ] konstruksi grafik pengetahuan [ 16 ], dan peningkatan basis data ilmiah [ 17 ]. Dibandingkan dengan LLM tujuan umum dan model NER siap pakai, penyempurnaan model NER ad hoc memiliki banyak keuntungan. Pertama, pengguna dapat secara fleksibel menentukan tipe entitas sesuai kebutuhan mereka. Kedua, biasanya lebih andal dan akurat karena data pelatihan spesifik domain yang dikurasi. Ketiga, model NER yang disempurnakan umumnya lebih cepat dan lebih dapat diinterpretasikan daripada LLM yang semakin besar, terutama ketika diterapkan dalam skala besar. Akhirnya, ia memiliki privasi yang lebih baik karena dapat dijalankan secara lokal tanpa mengirim data ke server eksternal. Keuntungan ini dibandingkan model universal yang ada sangat bermanfaat untuk memproses konten tekstual ilmiah dan karena itu dapat meningkatkan pengambilan informasi dan ekstraksi pengetahuan dalam informatika material. Namun demikian, penyempurnaan model NER untuk domain ilmiah kecil seperti MLIP juga memiliki tantangannya. Bisa dibilang yang paling penting adalah proses anotasi teks yang memerlukan anotasi manual oleh para ahli, yang bisa merepotkan, membosankan, dan rentan terhadap kesalahan. Alat anotasi yang mudah digunakan sangat berharga dalam mempercepat dan mempermudah proses tersebut. Akan tetapi, sebagian besar alat anotasi yang ada tidak memiliki fitur yang mudah digunakan yang disesuaikan dengan peneliti ilmu material dan tidak terintegrasi dengan pelatihan pembelajaran mesin.
Dalam karya ini, model NER untuk teks ilmiah MLIP dikembangkan dengan menyempurnakan LLM yang terspesialisasi dalam domain ilmu material. Data yang digunakan untuk penyempurnaan adalah abstrak makalah yang diberi anotasi secara manual oleh para ahli manusia. Untuk memfasilitasi proses anotasi manual, aplikasi web dikembangkan berdasarkan kerangka kerja Flask yang menyediakan antarmuka pengguna grafis (GUI) yang mudah digunakan untuk anotasi dan pemeriksaan akhir. Kemampuan inferensi untuk teks MLIP dalam distribusi (ID) baru dan teks di luar distribusi (OOD) (topik lain tetapi terkait dengan ilmu material) dievaluasi menggunakan presisi, perolehan kembali, dan skor F1. Akhirnya, kesalahan prediksi yang dibuat oleh model NER dianalisis, dan batasan model serta arah untuk perbaikan di masa mendatang didiskusikan. Pendekatan kami berbeda dari metode yang ada dengan menggabungkan data pelatihan yang diberi anotasi oleh ahli dengan alat anotasi khusus yang dirancang untuk menyederhanakan pelabelan manual dan pelatihan pembelajaran mesin.
2 Metode
2.1 Alur Umum
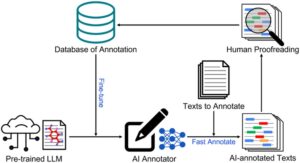
Alur kerja umum dalam karya ini terutama terdiri dari fine-tuning model NER dan persiapan data anotasi, seperti yang ditunjukkan pada Gambar 1. Untuk memulai, LLM yang telah dilatih sebelumnya bernama MaterialsBERT [13c] diimpor dari Hugging Face. MaterialsBERT adalah LLM yang mengkhususkan diri dalam domain ilmu material, yang awalnya dikembangkan melalui fine-tuning model PubMedBERT [ 18 ] (dilatih dengan literatur biomedis) menggunakan 2,4 juta abstrak ilmu material. Berdasarkan model dasar BERT [ 19 ], MaterialsBERT memiliki sekitar 110 juta parameter model, jauh lebih sedikit daripada LLM canggih dengan miliaran jika tidak triliunan parameter. Ini menunjukkan bahwa model kita bisa jauh lebih cepat untuk memproses sejumlah besar data setelah diterapkan. Kepala linier akan ditambahkan ke encoder untuk tugas klasifikasi entitas. Kumpulan awal teks yang dianotasi secara manual disimpan dalam database dalam format JSON, yang akan digunakan untuk fine-tuning LLM. LLM yang telah disetel dengan baik kemudian akan digunakan sebagai anotator AI untuk membuat anotasi teks baru secara berkelompok, yang berpotensi menghemat banyak tenaga manusia untuk membuat anotasi teks dari awal. Para ahli manusia mengoreksi anotasi baru ini, dan koreksi yang dibuat akan secara otomatis disimpan ke dalam basis data. Perulangan yang terdiri dari penyempurnaan, anotasi kelompok, dan pemeriksaan dapat diulang hingga mencapai kinerja prediksi yang diinginkan. Anotator AI akhir akan digunakan sebagai model NER.
2.2 Anotasi Data
Pedoman yang jelas dan anotasi yang konsisten sangat penting untuk data berkualitas tinggi dan selanjutnya, kinerja model. Namun, ini merupakan tugas yang menantang karena sifat ambigu bahasa manusia dan ketergantungan pada konteks. Dalam karya ini, delapan kelas digunakan untuk membuat anotasi teks terkait MLIP, termasuk ‘MATERIAL’, ‘MLIP’, ‘PROPERTI’, ‘FENOMENA’, ‘SIMULASI’, ‘NILAI’, ‘APLIKASI’, dan ‘LAINNYA’. Definisi dan contohnya untuk tugas NER kami dijelaskan dalam Tabel 1 , dan aturan anotasi khusus untuk setiap kelas dirinci dalam Informasi Tambahan (SI).
| Nama kelas | Contoh |
|---|---|
| BAHAN | “Cu”, “paduan”, “lowongan”, “HCP”, “sistem fisikokimia” |
| Bahasa Indonesia: MLIP | “analisis tetangga spektral”, “jaringan saraf” |
| MILIK | “sifat mekanik”, “permukaan energi potensial” |
| GEJALA | “reaksi kimia”, “deformasi geser” |
| SIMULASI | “simulasi dinamika molekul”, “potensial interatomik” |
| NILAI | “beberapa orde besaran lebih rendah”, “hingga 2500 K” |
| APLIKASI | “semikonduktor”, “ilmu material” |
| LAINNYA | “yang”, “memiliki”, “sementara” |
Meskipun tersedia panduan yang terdefinisi dengan baik, anotasi teks secara manual masih dapat menjadi proses yang memakan waktu dan rawan kesalahan. Selain itu, panduan sering kali fleksibel dan dapat berubah karena semakin banyak teks yang dianotasi. Ini memerlukan alur kerja proofreading dan modifikasi yang mudah digunakan. Untuk mencapai ini, aplikasi web dengan GUI yang mudah digunakan untuk anotasi dan proofreading bernama AnnoApp dikembangkan berdasarkan kerangka kerja Flask. Fungsionalitas AnnoApp dijelaskan sebagai berikut. Untuk anotasi, AnnoApp pertama-tama membagi paragraf input menjadi kata-kata dan tanda baca yang terpisah. Kemudian pengguna dapat memilih nama kelas (dengan mengklik salah satu nama kelas di atas) dan memilih kata-kata dan tanda baca (mengklik kotak) yang termasuk dalam kelas ini. Item yang tidak dipilih akan ditetapkan sebagai kelas ‘LAINNYA’. Anotasi akan dikonversi ke format JSON untuk pelatihan ML dan disimpan ke database SQL. Untuk proofreading, AnnoApp dapat memuat anotasi yang ada dari database. Pemeriksaan dapat dilakukan langsung di GUI yang sama dengan anotasi. Anotasi yang dikoreksi akan disimpan di basis data. Gambar 2a menunjukkan satu entri dari halaman indeks tempat semua data tersimpan dicantumkan, termasuk judul, teks, dan anotasi opsional dalam format JSON. Tautan ‘Anotasi’ akan membawa pengguna ke GUI untuk anotasi dan pemeriksaan, seperti yang diilustrasikan pada Gambar 2b .

2.3 Deskripsi Model
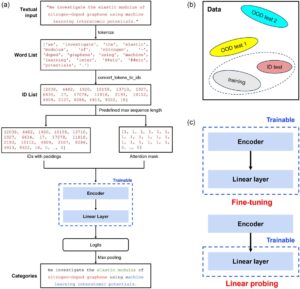
Proses tokenisasi dan pelatihan dijelaskan sebagai berikut dan diilustrasikan dalam Gambar 3. Arsitektur model umum terdiri dari tokenizer, encoder, dan kepala linier terlampir untuk tugas klasifikasi multikelas. Baik tokenizer maupun encoder diimpor dari model MaterialsBERT. Untuk memulai, input tekstual seperti paragraf dipecah menjadi urutan token yang akan digunakan untuk pemrosesan hilir. Tokenizer memecah kata-kata di luar kosakata seperti ‘interatomic’ menjadi unit subkata [‘inter’, ‘##ato’, ‘##mic’], di mana simbol “##” menunjukkan bahwa subkata berikutnya adalah kelanjutan dari subkata sebelumnya. Ini membantu mengurangi ukuran kosakata, menghasilkan memori dan efisiensi komputasi yang lebih baik. Kosakata [ 18 ] yang digunakan dalam pekerjaan ini terdiri dari sekitar 30.000 token khusus untuk domain biomedis yang tumpang tindih dengan ilmu material tempat konsep MLIP berada. Kemudian, token dikonversi ke ID token yang sesuai berdasarkan kosakata tokenizer. Selanjutnya, padding (menambahkan token ‘[PAD]’ khusus) atau truncation (memotong urutan) dilakukan untuk memastikan bahwa urutan ID token sesuai dengan panjang urutan maksimum yang telah ditetapkan sebelumnya (512 dalam karya ini). Selain itu, attention mask dibuat untuk menunjukkan token mana yang merupakan konten aktual dan mana yang merupakan padding. Urutan ID dan attention mask dimasukkan ke dalam encoder sebagai input. Untuk melakukan klasifikasi multikelas, linear head ditambahkan ke encoder, yang menghasilkan vektor logit dengan panjang yang sama dengan jumlah kelas yang telah ditetapkan sebelumnya. Akhirnya, max pooling dilakukan pada logit untuk membuat prediksi kelas. Misalnya, jika vektor logit adalah [0,1, 0,3, 0,2] untuk Kelas 1, 2, dan 3 yang telah ditetapkan sebelumnya, model memprediksi token sebagai Kelas 2 karena 0,3 adalah angka terbesar. Sebagai masalah klasifikasi multikelas, kinerja model dievaluasi oleh presisi tertimbang, recall, dan skor F1, yang dinyatakan sebagai

di mana bobot untuk kelas c w c adalah jumlah instance untuk kelasmathematical equationdibagi dengan jumlah semua instance;mathematical equationadalah jumlah kelas yang terlibat dalam perhitungan (dalam kasus ini, kelas ‘LAINNYA’ dikecualikan); P c , R c , dan F 1, c adalah presisi, recall, dan skor F1 untuk Kelas c , dinyatakan sebagai

di mana TP c , FP c , dan FN c adalah jumlah positif benar, positif salah, dan negatif salah untuk Kelas c , masing-masing. Tidak hanya jumlah contoh untuk kelas-kelas ini tidak seimbang tetapi juga signifikansinya. Misalnya, kelas ‘MLIP’ (jenis MLIP yang digunakan, misalnya) bisa dibilang lebih penting daripada kelas ‘APLIKASI’ (nama industri yang relevan seperti ‘semikonduktor’ yang disebutkan dalam teks, misalnya). Oleh karena itu, kerugian entropi silang tertimbang digunakan sebagai fungsi kerugian yang memungkinkan kita untuk menekankan kinerja prediktif untuk kelas yang berbeda seperti yang diinginkan, yang diberikan oleh
![]()
Di manamathematical equationadalah matriks logit;mathematical equationadalah vektor target;mathematical equationDanmathematical equationadalah vektor logit dan skalar target untuk sampelmathematical equation, masing-masing;mathematical equationadalah bobot label y i ; C adalah jumlah kelas;mathematical equationadalah ukuran batch;mathematical equationmenunjukkan sampel ke – i dalam minibatch. Pengoptimal Adam digunakan untuk memperbarui parameter model. Pelatihan model NER melibatkan beberapa hiperparameter. Nilai hiperparameter default yang digunakan dalam pekerjaan ini dirangkum dalam Tabel 2 .
| Nama hiperparameter | Nilai default |
|---|---|
Jumlah data pelatihan, |
60 |
| Vektor bobot kelas | (1,0, 1,0, 1,0, 1,0, 1,0, 0,5, 0,5, 0,5) |
Ukuran batch, |
1 |
| Panjang urutan maksimum | 512 |
| Kecepatan pembelajaran untuk penyempurnaan | 0,00005 |
| Kecepatan pembelajaran untuk penyelidikan linier | 0,001 |
Satu set data pelatihan dan tiga set data pengujian berbeda yang terdiri dari teks-teks yang diberi anotasi secara manual digunakan dalam studi ini. Set data pelatihan terdiri dari 72 abstrak makalah ‘MLIP’, dan setiap set data pengujian terdiri dari 9 abstrak makalah. Set data pengujian pertama terdiri dari abstrak makalah ‘MLIP’ yang berbeda dari set data pelatihan dan disebut sebagai set ‘pengujian ID’. Set data pengujian kedua dan ketiga adalah OOD, disebut sebagai set ‘pengujian OOD 1’ dan ‘pengujian OOD 2’. Set ‘pengujian OOD 1’ terdiri dari abstrak makalah tentang ‘simulasi MD dan pembelajaran mesin untuk nanomaterial’ oleh penulis makalah ini; set ‘pengujian OOD 2’ terdiri dari abstrak tentang ‘metamaterial optik’. Karena ‘metamaterial optik’ adalah topik yang kurang terkait dengan ‘MLIP’ daripada ‘simulasi MD dan MLIP untuk nanomaterial’, distribusi ‘pengujian OOD 2’ lebih jauh dari data pelatihan daripada ‘pengujian OOD 1’. Hubungan dataset ini diilustrasikan dalam Gambar 3b di mana lingkaran mewakili distribusi data dari dataset yang berbeda. Performa pada data OOD berfungsi sebagai indikator seberapa baik model telah mempelajari fitur linguistik yang dapat digeneralisasikan daripada hanya menghafal pola pelatihan. Selain itu, skema pelatihan penyelidikan linier diusulkan sebagai alternatif untuk fine-tuning. Tidak seperti fine-tuning di mana semua parameter model dapat dilatih, dalam penyelidikan linier hanya parameter lapisan akhir yang dapat dilatih dan semua parameter encoder ditetapkan, seperti yang diilustrasikan dalam Gambar 3c . Studi telah menunjukkan bahwa penyelidikan linier berkinerja lebih baik untuk kasus OOD daripada fine-tuning [ 20 ]. Alasan mereka adalah bahwa fine-tuning terkadang dapat membuat model terlalu terspesialisasi pada domain pelatihan, sementara penyelidikan linier lebih baik mempertahankan kemampuan asli LLM yang telah dilatih sebelumnya yang kondusif untuk generalisasi OOD.
3 Hasil dan Pembahasan
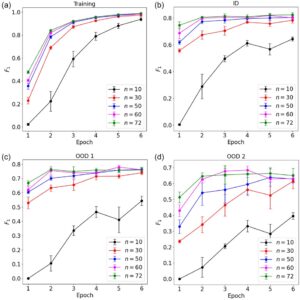
Kita mulai dengan menilai berapa banyak data pelatihan yang dibutuhkan dalam masalah NER ini. Model dilatih dengan 10, 30, 50, 60, 72 anotasi pelatihan, dan setiap model yang dilatih dievaluasi oleh metrik kinerja pada dataset pelatihan, uji ID, uji OOD 1, dan uji OOD 2. Plot skor F1 versus periode pelatihan untuk keempat dataset ditunjukkan pada Gambar 4. Untuk dataset pelatihan, skor F1 terus meningkat dengan lebih banyak data pelatihan yang digunakan dan konvergen ke 1, yang menunjukkan bahwa model telah mempelajari data pelatihan dengan baik. Untuk semua dataset pengujian, secara umum skor F1 meningkat dengan lebih banyak data pelatihan yang digunakan. Namun demikian, kinerjamathematical equationDanmathematical equationsudah menjadi sebanding, danmathematical equationbahkan mengunggulimathematical equationuntuk data pengujian OOD 2 pada Epoch 3 dan 4. Hal ini menunjukkan bahwa penggunaan lebih banyak data pelatihan mungkin tidak menghasilkan peningkatan kinerja yang substansial.mathematical equationakan digunakan sebagai jumlah default data pelatihan untuk sisa pemodelan dalam pekerjaan ini. Dari Gambar 4b–d , diamati bahwa skor F1 tertinggi yang dicapai untuk dataset uji ID, uji OOD 1, dan uji OOD 2 masing-masing sekitar 0,8, 0,75, dan 0,7, semuanya dalam waktu sekitar 3 periode. Ini menunjukkan bahwa model kami memiliki properti pembelajaran few-shot yang dapat diperoleh dan diadaptasi model dengan cepat dengan data minimal. Metrik lain termasuk kerugian pelatihan, presisi, dan perolehan kembali untuk semua dataset disediakan dalam SI (Gambar S1 dan S2, Informasi Pendukung).
Berikutnya, efek bobot kelas pada kinerja model NER dibahas. Dalam karya ini, vektor bobot kelas adalah 8 dimensi dan mengambil nilai kontinu, dan karenanya tidak mungkin untuk menggunakan semua kemungkinan secara brute force. Vektor bobot kelas default (1.0, 1.0, 1.0, 1.0, 1.0, 0.5, 0.5, 0.5) cukup menekankan kelas ‘MATERIAL’, ‘MLIP’, ‘PROPERTY’, ‘PHENOMENON’, dan ‘SIMULATION’ dengan menetapkan bobot yang lebih kecil ke kelas ‘VALUE’, ‘APPLICATION’, dan ‘OTHER’. Karena kelas ‘OTHER’ tidak relevan dengan tujuan model NER, mungkin agak menggoda untuk menetapkan bobotnya ke 0. Di sini kami membandingkan hasil pilihan bobot ini (1.0, 1.0, 1.0, 1.0, 1.0, 0.5, 0.5, 0.0), bobot default, dan bobot seragam (1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0). Skor F1 pada set data uji model yang dilatih dengan vektor bobot kelas ini ditunjukkan pada Gambar 5a–c . Kerugian pelatihan, semua metrik untuk data pelatihan, presisi dan perolehan kembali untuk data uji, dan contoh prediksi disediakan dalam SI (Gambar S3–S6, Informasi Pendukung). Ditunjukkan bahwa jika bobot kelas ‘OTHER’ ditetapkan ke 0, skor F1 sangat rendah dan tidak membaik dengan pelatihan dengan lebih banyak epoch. Dari contoh tersebut (Gambar S6, Informasi Pendukung) dapat diamati bahwa model tidak membuat prediksi kelas ‘LAINNYA’. Hal ini dikarenakan model terus menerima sinyal pelatihan untuk kelas lain dengan bobot bukan nol dan belajar untuk memprioritaskan kelas-kelas ini dalam distribusi probabilitasnya. Akibatnya, presisi sangat rendah sementara perolehan kembali kurang terpengaruh secara komparatif (Gambar S5, Informasi Pendukung). Selain itu, bobot kelas default menghasilkan kinerja yang lebih baik dibandingkan bobot seragam, terutama untuk set uji OOD 2. Dalam kerangka kerja saat ini, vektor bobot dapat disesuaikan secara fleksibel berdasarkan preferensi pengguna atas kelas mana yang akan diprioritaskan. Hal ini menunjukkan bahwa strategi pembobotan kelas dapat digunakan untuk mengurangi ketidakseimbangan data, memastikan bahwa entitas yang langka tetapi penting dipelajari secara memadai oleh model.
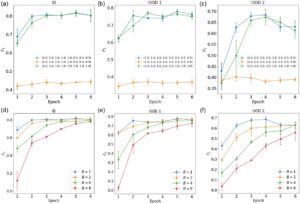
Selanjutnya, pengaruh ukuran batch dipelajari. Skor F1 pada dataset uji model yang dilatih dengan ukuran batch yang berbeda (mathematical equation) hingga 6 periode ditunjukkan pada Gambar 5d–f . Kerugian pelatihan, semua metrik untuk data pelatihan, dan presisi serta perolehan kembali untuk data uji disediakan dalam SI (Gambar S7–S9, Informasi Pendukung). Hasil menunjukkan bahwa ukuran batch yang kecil umumnya berkinerja lebih baik di berbagai metrik. Namun, terlihat bahwa ukuran batch yang lebih besar (mathematical equation) masih menunjukkan peningkatan kinerja pada epoch 6 dimanamathematical equationkasusnya telah mencapai titik jenuh. Oleh karena itu, mungkin saja model yang dilatih dengan ukuran batch yang lebih besar dapat mencapai kinerja yang sebanding dengan periode pelatihan yang lebih banyak. Untuk menguji hal ini, kami membandingkan model yang dilatih dengan ukuran batchmathematical equationsampai 6 epoch dan denganmathematical equationhingga 20 epoch. Kerugian pelatihan dan kinerjanya pada berbagai kumpulan data disediakan dalam SI (Gambar S10 dan S11, Informasi Pendukung). Diperlihatkan bahwamathematical equationmodel mengejar ketinggalan denganmathematical equationmodel sehubungan dengan kerugian pelatihan dan kinerja pada pelatihan, tes ID, dan set tes OOD 1 di sekitar epoch 12. Namun,mathematical equationmodel masih mengunggulimathematical equationmodel untuk set uji OOD 2. Berdasarkan hasil ini, meskipun ukuran batch yang lebih besar mengurangi waktu pelatihan yang sangat lama, ukuran batch yang lebih besar kurang efisien datanya dibandingkan ukuran batch yang lebih kecil dan menghasilkan kinerja generalisasi yang lebih buruk pada data OOD. Kami juga menemukan bahwa fine-tuning umumnya berkinerja lebih baik daripada linear probing, dan metrik kerugian pelatihan dan presisi/pengingatannya disediakan dalam SI (Gambar S12 dan S13, Informasi Pendukung). Meskipun demikian, linear probing jauh lebih cepat daripada fine-tuning karena parameter yang dapat dilatih jauh lebih sedikit.
Akhirnya, kami meneliti contoh hasil NER dari set uji ID, seperti yang diilustrasikan dalam Gambar 6. Teks berkode warna adalah prediksi model NER. Kotak merah menunjukkan kata atau tanda baca yang kelas prediksinya berbeda dari kelas yang diberi anotasi (ditunjukkan oleh teks di sebelahnya). Kasus prediksi ini, yang terdiri dari 223 kata dan tanda baca, memiliki akurasi total 93,7%, presisi tertimbang 0,888, recall tertimbang 0,940, dan skor F1 tertimbang 0,907. Menariknya, diamati bahwa beberapa ‘kesalahan’ yang dibuat oleh model NER sebenarnya adalah keputusan yang wajar. Misalnya, model mengkategorikan ‘anode’, ‘pengisian’, dan ‘situs tetrahedral’ sebagai ‘APPLICATION’, ‘PHENOMENA’, dan ‘MATERIAL’, masing-masing, sedangkan kebenaran dasarnya adalah ‘MATERIAL’, ‘OTHER’, dan ‘OTHER’. Seseorang dapat berargumen bahwa prediksi model tidak kurang ‘benar’ daripada kebenaran dasar. Contoh ini menggambarkan kemampuan model melampaui apa yang ditunjukkan oleh metrik kinerja dan memamerkan kemampuan linguistiknya dalam memproses informasi tekstual dari domain ilmiah tertentu. Metrik berbasis akurasi, meskipun berguna, tidak selalu membedakan antara kesalahan sebenarnya dan klasifikasi alternatif yang valid secara semantik. Meskipun protokol anotasi terstruktur kami (Tabel S1, Informasi Pendukung), beberapa tingkat subjektivitas tetap melekat dalam bahasa ilmiah yang kompleks. Di masa mendatang, kami akan mengeksplorasi pengintegrasian klasifikasi entitas berbasis keyakinan [ 21 ], kuantifikasi ketidakpastian [ 22 ], atau validasi manusia-dalam-lingkaran [ 23 ] untuk menangkap nuansa tugas NER khusus domain dengan lebih baik.

Sementara kami terutama berfokus pada penerapan NER untuk ekstraksi informasi dari literatur MLIP, pendekatan ini dapat berkontribusi pada pengembangan MLIP universal. Salah satu tantangan utama dalam mengembangkan MLIP universal adalah kebutuhan akan data pelatihan yang beragam dan berkualitas tinggi yang mencakup berbagai macam material, lingkungan atom, dan jenis potensial interaksi. NER dapat membantu dalam upaya ini dengan mengekstraksi informasi yang relevan secara sistematis, seperti parameter medan gaya, energi kohesif, atau istilah interaksi khusus material, dari kumpulan besar literatur dan basis data yang relevan. Model NER dan aplikasi web kami berpotensi membantu mengotomatiskan konstruksi kumpulan data yang komprehensif untuk pelatihan MLIP universal, mengurangi upaya manual yang diperlukan untuk menyusun informasi tersebut. Selain itu, kerangka kerja NER kami sangat dapat digeneralisasi dan terbukti efektif untuk data uji OOD. Oleh karena itu, kami percaya bahwa kerangka kerja saat ini dapat membantu dalam ekstraksi pengetahuan untuk cakupan ilmu material yang lebih luas, seperti penelitian penyimpanan energi dengan mengidentifikasi komponen-komponen utama secara efektif seperti material anoda dan katoda serta ilmu polimer dengan membangun basis data untuk teknik pemrosesan dan sifat mekanis. Namun demikian, pendekatan kami menghadirkan beberapa keterbatasan dan ruang untuk perbaikan. Pertama, fine-tuning merupakan proses komputasi yang mahal dan dapat menjadi sangat menantang bagi LLM mutakhir dengan miliaran parameter. Kedua, fine-tuning memerlukan akses ke parameter model, sedangkan saat ini banyak model canggih tidak memilikinya. Untuk mengatasi tantangan ini, dalam pekerjaan mendatang kami akan menggabungkan teknik seperti rekayasa cepat dalam tugas NER, yang tidak memerlukan fine-tuning model dan dapat fleksibel dalam mendefinisikan kelas.
4 Kesimpulan
Dalam karya ini, kami mengembangkan model NER untuk literatur MLIP dengan menyempurnakan LLM yang telah dilatih sebelumnya. Untuk meningkatkan proses anotasi teks yang secara tradisional rumit, kami membangun aplikasi web yang mudah digunakan untuk anotasi dan pemeriksaan akhir, yang terintegrasi dengan mulus ke dalam prosedur pelatihan. Hasil penelitian menunjukkan bahwa model NER dapat mengidentifikasi entitas teknis dengan skor F1 sebesar 0,8 untuk abstrak makalah MLIP baru dengan hanya 60 abstrak makalah sebagai data pelatihan. Selain itu, model ini mencapai skor F1 hingga 0,75 untuk teks ilmiah pada berbagai topik. Dengan memeriksa prediksi model yang sebenarnya, kami menemukan bahwa beberapa ‘kesalahan’ yang dibuat oleh model NER sebenarnya adalah keputusan yang wajar, yang menunjukkan kemampuan model tersebut melampaui apa yang ditunjukkan oleh metrik kinerja. Karya ini menunjukkan kemampuan linguistik pendekatan NER dalam memproses informasi tekstual dari domain ilmiah tertentu dan berpotensi untuk mempercepat penelitian materi menggunakan model bahasa dan berkontribusi pada alur kerja yang berpusat pada pengguna.