Abstrak
Volume segmentasi adalah kumpulan data voksel yang sering digunakan dalam pembelajaran mesin, konektomika, dan ilmu pengetahuan alam. Ukurannya yang besar membuat kompresi sangat diperlukan untuk penyimpanan dan pemrosesan, termasuk visualisasi waktu nyata yang dibatasi memori video GPU. Volume Segmentasi Terkompresi Cepat (CSGV) [PD24] menyediakan kompresi per bata yang kuat dan akses acak pada tingkat bata. Namun, voksel dalam bata harus didekode secara serial sehingga rendering memerlukan penyimpanan sementara bata penuh yang terlihat, yang menghabiskan memori ekstra. Tanpa penyimpanan sementara, mengakses voksel dapat memiliki overhead dekode kasus terburuk hingga bata penuh (biasanya lebih dari 32.000 voksel). Kami menyajikan CSGV-R yang menyediakan akses acak multiresolusi sejati pada tingkat per-voksel. Kami memanfaatkan Pohon Wavelet berbentuk Huffman untuk akses acak ke pengodean panjang bit variabel dan operasi peringkatnya untuk mengkueri offset palet label dalam bata. Visualisasi volume segmentasi real-time kami menghilangkan artefak decoding dari CSGV dan merender volume CSGV-R tanpa menyimpan cache pada waktu render yang lebih cepat. CSGV-R memiliki rasio kompresi yang sedikit lebih rendah daripada CSGV, tetapi mengungguli Neuroglancer, teknik kompresi canggih dengan akses acak yang sebenarnya, dengan set data 2x hingga 4x lebih kecil pada rasio antara 0,648% dan 4,411% dari ukuran volume asli.
1. Pendahuluan
Volume segmentasi umumnya digunakan dalam berbagai domain seperti konektomika, pembelajaran mesin, atau ilmu pengetahuan alam. Sebaiknya manfaatkan sumber daya komputasi dan pemrosesan paralel GPU saat bekerja dengan volume segmentasi skala besar, tetapi memori GPU yang tersedia dapat dengan cepat menjadi faktor pembatas. Bekerja dengan volume segmentasi terkompresi dapat mengatasi masalah ini, namun, metode kompresi yang ada tidak cocok untuk pemrosesan dan rendering berbasis GPU, atau memiliki kekurangan yang signifikan, terutama tidak menawarkan kompresi yang kuat dan akses acak pada saat yang bersamaan.
Metode canggih Fast Compressed Segmentation Volumes (CSGV) [ PD24 ] mengodekan blok-blok volume segmentasi secara individual dalam mode multiresolusi dan memungkinkan akses acak pada level ini. Namun, dalam sebuah blok, voksel hanya dapat didekode dari aliran operasi yang tersimpan dalam cara serial yang ketat, yang melarang akses acak yang sebenarnya. Ini memiliki kelemahan, misalnya untuk merender volume: Pertama, cache untuk blok-blok yang didekode diperlukan yang menyimpan lebih banyak voksel daripada yang diperlukan dan menghabiskan memori yang signifikan—hingga gigabita sebagai tambahan dari data yang dikompresi. Pada resolusi rendering tinggi di mana banyak blok diminta pada tingkat detail yang paling halus, ukuran cache dapat dengan mudah melebihi memori GPU yang tersedia. Karena hasil yang semakin berkurang dari peningkatan laju kompresi, kami menyarankan bahwa metode baru mengatasi ketergantungan ini pada cache yang besar untuk mengurangi memori rendering secara keseluruhan. Kedua, tidak ada cara yang layak untuk mengakses voksel jika tidak ada dalam cache. Untuk tugas dengan akses voxel tunggal acak yang tidak koheren, overhead decoding akan signifikan karena batu bata selalu harus didekode hingga voxel yang diminta.
Dalam makalah ini, kami memperkenalkan struktur data terkompresi baru untuk volume segmentasi dengan akses acak sebenarnya ke voksel. Berdasarkan pengodean multiresolusi kompak CSGV, komponen utama Volume Segmentasi Terkompresi Akses Acak (CSGV-R) kami adalah menggunakan pengodean pohon wavelet untuk mengindeks data terkompresi. Pohon wavelet digunakan dalam pengindeksan teks dan bidang terkait, dan sejauh pengetahuan kami, kami adalah yang pertama mengadaptasi dan menggunakannya dalam konteks rendering. Struktur data kami tidak memerlukan pengodean sistem numerik asimetris (ANS) panjang bit variabel serial [ Dud13 ] seperti CSGV, dan dengan demikian lebih ramah GPU. Kami mengurangi overhead implementasi dan kueri pohon wavelet kami untuk melampaui kinerja render CSGV. Akses acak kami menghilangkan kebutuhan untuk melakukan caching pada tingkat bata: kami mengevaluasi volume segmentasi rendering tanpa melakukan caching apa pun, dan dengan melakukan caching voksel individual secara langsung. Singkatnya, kontribusi kami adalah:
- metode kompresi lossless dan akses acak yang ramah GPU untuk volume segmentasi,
- perender yang efisien dengan caching voxel individual yang diaktifkan akses acak (menggunakan hashing Cuckoo), dan
- implementasi shader GPU matriks wavelet berbentuk Huffman yang dioptimalkan untuk mengindeks data volume terkompresi.
2. Pekerjaan dan Latar Belakang Terkait
Berikut ini, kami memperkenalkan karya terkait dari segmentasi, kompresi volume, dan visualisasi, serta pohon wavelet.
2.1. Segmentasi Volume Kompresi
Banyak sekali karya yang ada mengenai kompresi gambar dan volume skala abu-abu [ BTB*22 , BRGIG*14 ]. Kompresor semacam itu diterapkan pada data gambar jika dipasangkan dengan volume segmentasi [ MJB*21 ]. Namun, mereka jarang digunakan secara langsung untuk volume segmentasi karena kompresi tersebut biasanya tanpa kehilangan data [ MHL*17 , Goo16 , PD24 ] dan kontennya, label klasifikasi integer, berperilaku berbeda dari data gambar. Pengecualiannya adalah kompresor gambar tanpa kehilangan data seperti PNG [ ATAS21 ]. Kompresi tujuan umum tanpa kehilangan data, misalnya gzip, digunakan dalam format file terkompresi seperti hdf5 [ HDF ] dan NIfTI [ LM14 ]. Untuk segmentasi biner, pohon oktaf-voksal-sparse [ LK10 ] dan graf-asiklik-terarah [ KSA13 ] dapat diterapkan. Untuk data dengan lebih banyak label, nilai label dan okupansi dapat dipisahkan dalam kotak pembatas lokal [ WPD24 ] tetapi laju kompresi terbatas. Compresso [ MHL*17 ] mengodekan wilayah label dalam jendela kecil sebagai border bit mask dan palet label. Jendela dapat diakses secara acak, tetapi laju kompresi yang kuat hanya tercapai saat menerapkan kompresi LZMA global tambahan, yang membuat akses acak tidak mungkin dan tidak dapat diparalelkan. Mixture Graph [ ATAS21 ] membuat hierarki multiresolusi yang dipadatkan grafik dari distribusi label. Format prakomputasi Google Neuroglancer [ Goo16 ] adalah pengodean per bata yang menyimpan palet label untuk setiap bata dan sejumlah bit tetap per pengindeksan voxel ke dalamnya. Ini adalah format tercepat, menawarkan akses acak sebenarnya hingga ke level voxel, tetapi memiliki laju kompresi di bawah standar. CSGV [ PD24 ] adalah kompresor volume segmentasi tercanggih dalam hal laju kompresi dan juga beroperasi per bata. Ini mengodekan hierarki multiresolusi label sebagai aliran operasi penugasan label. Aliran dikompresi dengan pengodean panjang bit variabel ANS [ Dud13 ]. Sementara bata dapat diakses secara acak, akses dalam bata, yang mencakup hingga beberapa ribu voksel, harus terjadi secara serial. Kompresor volume segmentasi multiresolusi kami adalah alternatif untuk CSGV yang menawarkan akses acak hingga ke tingkat voksel seperti di Google Neuroglancer tetapi dengan tingkat kompresi yang mendekati CSGV.
2.2. Visualisasi Volume Segmentasi
Segmentasi sering divisualisasikan dalam kerangka kerja pelabelan atau pemeriksaan akhir sebagai irisan 2D atau jaring segitiga 3D raster [ PHK04 , BBB*17 , BSL18 , AABH*16 ]. Penggabungan daerah voxel merupakan praproses, atau hanya didukung untuk beberapa label [ Lem10 , QDB11 , LC87 ]. Metode visualisasi portabel sering berbasis web [ Goo16 , BBB*17 ] sementara rendering offline dapat menggunakan perender fotorealistik [ Ble18 , VMM*23 ] dan perangkat keras terdistribusi [ MAF07 ] dengan waktu render yang lebih lama dan aksesibilitas yang lebih rendah. Untuk volume segmentasi skala besar, format penyimpanan jauh memungkinkan akses yang dialirkan sebagian dengan caching [ MSL22 ] seperti yang diterapkan oleh Google Neuroglancer [ Goo16 ] dan Webknossos [ BBB*17 ] yang keduanya merender irisan 2D dan jaring 3D subset. Ray marching dapat digunakan saat data voxel dirender secara langsung, bukan representasi mesh [ ATAS21 , PD24 ]. Jika volume sesuai dengan memori utama, perender pada perangkat keras konsumen GPU tunggal dapat mengalirkan dan menyimpan sebagian volume dari memori utama ke memori video GPU (VRAM) [ BAAK*13 , BMA*18 ]. Atau, representasi volume yang terkompresi disimpan dalam VRAM untuk mendekode sebagian dan menyimpan sebagian wilayah yang terlihat dalam alur kerja yang lebih cepat dan sepenuhnya berbasis GPU [ PD24 ]. Dengan rendering domain kompresi, penyimpanan sementara tidak diperlukan [ WPD24 , Goo16 ]. Werner dkk. [ WPD24 ] mengodekan hunian label di dalam kotak pembatas yang terpisah, membuat kompresinya cocok untuk raytracing yang dipercepat perangkat keras. Metode ini memerlukan kelangkaan dalam data dan mencapai kompresi yang lebih lemah daripada CSGV. Grafik Campuran [ ATAS21 ] memecahkan masalah penyaringan warna, yang hanya dapat diterapkan dengan fungsi transfer pasca-klasifikasi [ EHK*06 ] untuk volume segmentasi multi-resolusi. Volume Conductor [ LAB*24 ] mengatasi kekacauan visual dalam volume berlabel padat dengan manajemen visibilitas berbasis label. Volume Puzzle [ AAAT*22 ] menawarkan pembuatan fungsi transfer semi-otomatis untuk volume segmentasi. Perender kami menyimpan volume terkompresi akses acak dalam VRAM untuk alur kerja perenderan domain kompresi berbasis GPU sepenuhnya dengan caching voxel opsional.
2.3. Akses dan Peringkat Kueri pada Vektor Bit
Vektor bit adalah teks B di atas alfabet biner {0,1}. Pada vektor bit, kami tertarik pada dua jenis kueri: akses ( i ) = B [ i ] dan peringkat α ( i ) = |{ j < i: B [ j ] = α}| untuk α ∈ {0,1} yang mengembalikan berapa kali α terjadi sebelum i . Pada vektor bit, kueri ini dapat dijawab dalam waktu konstan [ Jac89 ]. Dalam praktiknya, pendekatan yang saat ini paling hemat ruang yang mempertahankan kinerja kueri yang wajar disebut peringkat datar [ Kur22 ]. Peringkat datar hanya membutuhkan 3,51 % ruang tambahan. Ide umumnya adalah untuk mempartisi vektor bit ke dalam blok dan untuk menyimpan jumlah 1 -bit dalam vektor bit hingga setiap blok dalam array (lihat [ Kur22 ] dan suplemen kami untuk detailnya).
2.4. Pohon Wavelet
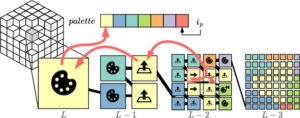
Pohon wavelet [ GGV03 ] adalah struktur data indeks yang dapat dikompresi dengan aplikasi dalam pengindeksan teks [ FM00 , GNP20 ], kompresi teks [ GVX11 , Mak12 ], dan geometri komputasional [ MN06 ]. Mereka menggeneralisasi, antara lain, kueri akses dan peringkat dari alfabet biner ke alfabet berukuran σ dan dapat menjawab kueri ini dalam waktu O (log σ). Kami sekarang memberikan gambaran singkat tentang pohon wavelet di sepanjang varian pada Gambar 2. Karena keterbatasan ruang, kami menghilangkan beberapa detail umum dan merujuk ke survei yang sangat baik pada pohon wavelet [ GVX11 , Mak12 ].

Struktur Pohon Wavelet. Setiap simpul pohon wavelet (kiri pada Gambar 2 ) mewakili satu subset dari keseluruhan teks T dan memiliki hingga dua anak. Subset ini berisi semua karakter T yang berada dalam satu subset alfabet, yaitu pohon wavelet membagi alfabet , bukan ruang teks. Akar di atas mempertimbangkan keseluruhan alfabet dan dengan demikian mewakili keseluruhan teks. Sekarang, anak kiri akar mewakili semua karakter di bagian bawah alfabet dan anak kanan mewakili semua karakter di bagian atas alfabet. Dengan kata lain, ketika akar mempertimbangkan alfabet Σ = [1,σ], anak kiri mempertimbangkan Σ ℓ = [1, σ/2] dan anak kanan mempertimbangkan Σ r = [σ/2 +1, σ] dikurangi pembulatan. Simpul yang tersisa didefinisikan secara rekursif dan kita berhenti pada kedalaman [log σ].
Kami menggunakan vektor bit untuk merepresentasikan karakter. Jika karakter berada di bagian bawah alfabet, kami menandainya dengan 0-bit. Jika tidak, ditandai dengan 1-bit. Di setiap simpul, kami hanya melihat karakter di subset yang direpresentasikan oleh simpul, yaitu, panjang total semua vektor bit di level pohon yang sama selalu | T |. Jalur merah pada Gambar 2 menyoroti kueri untuk akses T (8) = T [8] yang dimulai pada posisi i = 8 di simpul akar dan turun ke kiri atau kanan tergantung pada bit α di i . Semua karakter yang berbagi bit yang sama akan menjadi milik simpul yang sama di level berikutnya. Jadi, peringkat α ( i ) di simpul saat ini menentukan indeks berikutnya di simpul di level berikutnya. Dalam contoh kami, penurunan melalui pohon ini secara iteratif memperluas awalan bit karakter yang diberikan hingga semua bit diketahui. peringkat ω T beroperasi dengan cara yang sama: karena karakter yang sama ω ∈ Σ selalu berakhir di simpul yang sama, peringkat vektor bit di simpul tersebut sama dengan peringkat T ω . Untuk menemukan simpul tersebut, bit arah α di level l tidak diperoleh melalui akses tetapi merupakan bit ke- l dari kode ω (lihat suplemen kami untuk detailnya).
Dalam memori, pohon wavelet tidak disimpan menggunakan pointer: Pohon wavelet level-wise menggabungkan semua vektor bit pada level yang sama [ CKV24 ]. Representasi yang lebih efisien adalah matriks wavelet [ CNP15 ], yang merupakan pohon wavelet level-wise di mana node pada level yang sama telah diurutkan ulang untuk menyimpan satu akses dan/atau kueri peringkat per level dalam praktik. Karena ini hanyalah representasi memori tanpa pointer dari pohon wavelet, kami selalu merujuk struktur tersebut sebagai pohon wavelet , seperti konvensi dalam literatur.
Meningkatkan Kueri Pohon Wavelet. Akan tetapi, awalnya dirancang sebagai representasi alternatif pohon wavelet untuk alfabet besar, tata letak matriks wavelet [ CNP15 ] juga menyediakan kueri yang lebih cepat dalam praktik tanpa kekurangan apa pun. Lebih jauh, karena kesamaannya, semua hasil untuk pohon wavelet juga berlaku untuk matriks wavelet. Telah ada upaya lebih lanjut untuk meningkatkan kinerja kueri pohon wavelet (dan matriks) menggunakan pohon multi-ary [ FMMN07 , CKV24 ] dan hutan wavelet [ HBG*24 ].
Konstruksi Pohon Wavelet. Babenko dkk. [ BGKS15 ] dan Munro dkk. [ MNV16 ] menyajikan algoritma konstruksi sekuensial terbaik yang hanya memerlukan Gambarwaktu. Ada banyak lagi pekerjaan (teoretis dan praktis) tentang konstruksi pohon wavelet yang efisien dalam berbagai model komputasi [ Shu20 , Shu15 , FEFS17 , dFdS17 , CNS11 , Tis11 , Kan18 , EK19 , DFK20 , DEF*21 , DFKT23 ]. Perlu dicatat bahwa, sejauh pengetahuan kami, satu-satunya implementasi GPU pohon wavelet adalah oleh NVIDIA sebagai bagian dari pustaka NVBIO mereka [ NPS20 ].
Pohon Wavelet yang Dikompresi. Pohon wavelet dapat dengan mudah dikompresi. Untuk tujuan ini, kita dapat membangun pohon wavelet untuk teks terkompresi Huffman [ Huf52 ] (tepat pada Gambar 2 ). Jenis pohon wavelet ini disebut pohon wavelet berbentuk Huffman, karena kedalaman daun sekarang bergantung pada panjang kata kode karakter yang direpresentasikan. Pohon wavelet berbentuk Huffman ini hanya memerlukan | T |⌈ H 0 ( T )⌉(1 + o (1)) bit ruang. Di sini, H 0 ( T ) menunjukkan entropi orde ke-0, yaitu, jumlah ruang paling sedikit yang dapat dicapai saat mengodekan setiap simbol teks secara terpisah. Perhatikan bahwa kita tidak dapat menggunakan kode Huffman secara langsung, sebaliknya kita harus menggunakan CHC [ DEF*21 ] yang dinegasikan per bit, yang tidak memperburuk jaminan teoretis apa pun tetapi memberikan manfaat kode yang lebih kecil secara leksikografis lebih besar. Hal ini memungkinkan kita untuk memiliki pohon, di mana level yang lebih pendek semuanya berada di sisi kanan pohon, menyederhanakan navigasi pohon. Untuk kasus khusus kita pada Gambar 2 , tidak ada anak kanan yang ada sama sekali karena pola CHC yang diberikan. Sebagian besar kueri akses berakhir di kedalaman awal. Bagian 3 mencakup kode semu untuk kueri akses dan peringkat yang disederhanakan . Dalam karya ini, kita menggunakan pohon wavelet untuk mengompresi penyandian volume segmentasi kita dalam bentuk matriks wavelet berbentuk Huffman yang disederhanakan, yang mendukung kueri akses acak dan peringkat .
2.5. Volume Segmentasi Terkompresi Cepat
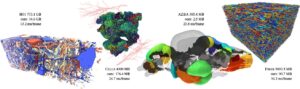
Volume segmentasi adalah grid 3D yang menyimpan label integer untuk setiap voksel. Voksel dengan label yang sama biasanya membentuk wilayah yang bersebelahan dan membagi ruang menjadi wilayah objek yang terpisah. Sementara volume segmentasi dapat menetapkan beberapa label ke satu voksel, kami fokus pada kasus yang paling umum di mana setiap voksel v ∈ ℕ 3 ditetapkan ke tepat satu label λ ∈ [0,2 32 ). CSGV [ PD24 ] adalah kompresi per bata untuk volume tersebut: Oleh karena itu, volume dibagi menjadi bata berukuran sama dengan b 3 voksel dengan b = 2 i , i ∈ ℕ; b biasanya adalah 16, 32, atau 64. Setiap bata di- (de-)kompresi sepenuhnya secara independen. Untuk setiap bata, CSGV pertama-tama membangun grid multi-resolusi volumenya dengan membagi dua bi -times; elemen yang dihasilkan dilambangkan sebagai node (Gambar 3 ). Kisi ini merepresentasikan [ L = log 2 ( b )] + 1 level detail (LOD) yang diindeks dengan l ∈ [0, L ]. Setiap node diberi label yang paling sering muncul dari 2 3 node anaknya pada LOD yang lebih halus berikutnya yang mencakup wilayah yang sama dalam volume segmentasi. Node kisi kemudian diserialisasikan dari LOD yang paling kasar hingga yang paling halus dan sepanjang kurva orde Z Morton dalam suatu LOD.
CSGV mengodekan label node grid sepanjang urutan pengindeksan ini dengan satu operasi per node, dan menyimpan palet label. Alih-alih menyimpan indeks node ke dalam palet secara eksplisit, penunjuk indeks i p diinisialisasi ke entri palet pertama dan bertambah setiap kali entri palet berikutnya dibaca. Operasi yang mungkin untuk sebuah node adalah
Gambarsalin label simpul induk,
Gambarsalin label simpul tetangga yang selaras sumbu,
Gambarbaca label di i p dari palet dan maju i p ,
Gambarbaca kembali label di i p – 1 dari palet,
Gambarbaca kembali label pada ip – δ dari palet.
Operasi tetangga Gambarselalu merujuk ke simpul tetangga di luar blok voxel 2 3 saat ini , yaitu tetangga dengan induk yang berbeda. Jika label tetangga ini belum didekodekan, induknya akan dirujuk sebagai gantinya (palang merah pada Gambar 3 ). Gambarmemerlukan penyimpanan tambahan nilai δ dalam aliran operasi.
Dalam penyandian CSGV Nibble-wise biasa, 3 bit per node cukup untuk menyimpan operasinya. Bit henti tambahan digunakan untuk menandai node yang semua node anaknya memiliki label yang sama. Node anak ini dapat dihilangkan dalam aliran penyandian yang menghasilkan sparsifikasi seperti Octree. Untuk kompresi yang lebih baik, CSGV menggunakan penyandian dengan panjang bit variabel (encoder ANS rentang [ Dud13 ]) untuk mengompresi aliran operasi bata. Perhatikan bahwa CSGV selalu mendekode bata sepenuhnya hingga LOD tertentu: Aliran operasi bata dilintasi dari LOD paling kasar hingga node terakhir dari LOD target. Selama pemrosesan operasi node, larik keluaran menyimpan sementara label yang ditetapkan oleh LOD yang lebih kasar untuk melacak label induk dan wilayah konstan dari bit henti.
3. Segmentasi Akses Acak Kompresi Volume
Kompresi aliran ANS yang digunakan dalam CSGV membuat akses acak menjadi tidak mungkin. Oleh karena itu, kami akan memadatkan aliran operasi simpul T [ i ] : ℕ ↦ Σ dengan pohon wavelet berbentuk Huffman, yang memungkinkan kompresi panjang bit variabel dan akses acak. Operasi Gambardalam CSGV memerlukan penyimpanan nilai δ sebagai nilai tambahan dalam aliran operasi. Karena nilai-nilai δ ini meningkatkan jumlah nilai yang muncul berbeda dalam aliran, kami menghilangkan operasi ini dalam CSGV-R kami dan hanya mendukung jarak referensi balik yang paling sering δ = 1 yang secara langsung dikodekan sebagai Gambar. Artinya, alfabet kami Gambarberukuran |Σ| = 6.
Kompresi panjang bit variabel bermanfaat karena operasi yang digunakan dalam CSGV terjadi pada frekuensi yang sangat berbeda. Kami menggunakan pohon wavelet berbentuk Huffman yang memetakan simbol ke pola bit, kode Huffman kanonik negasi bit-bijaksana (CHC) [ DEF*21 ]. CHC dibangun dari pohon Huffman, yaitu dari frekuensi operasi. Dalam CSGV, referensi induk adalah simbol yang paling sering, referensi tetangga lebih jarang, dan akses palet dan referensi kembali paling jarang terjadi. Polanya konsisten di seluruh set data dan domain [ PD24 ], yang memungkinkan untuk menentukan kode Huffman satu kali. Secara praktis untuk pengkodean Huffman, distribusi operasi secara kasar mengikuti (1/2) 1…7 . Gambar 2 (kanan) menunjukkan CHC yang dihasilkan untuk alfabet Σ kami. Panjang maksimum pola bit adalah 5 yang berarti bahwa pohon wavelet berbentuk Huffman kami menggunakan 5 level. Perhatikan bahwa CHC mengikuti tata letak sederhana, mirip dengan pengkodean RICE [ RP71 ] di mana jumlah bit 0 yang berurutan menentukan operasinya. Karena alasan ini, pohon wavelet kami tidak mengandung simpul anak kanan, yaitu setiap bit 1 mengakhiri simbol (Gambar 2 tengah).
Algoritma 1 Gambar menghitung indeks simpul multi-grid yang diberikan oleh kode Morton n di Gambardalam aliran operasinya. n dan Gambardilewatkan dengan referensi. T l adalah indeks aliran simpul pertama di setiap Gambaradalah vektor bit henti.

Kompresi Pohon Wavelet. Saat mengompresi bata volume, pertama-tama kami mengodekan label multi-grid-nya dari tingkat paling kasar ke paling halus ke dalam daftar operasi seperti dalam CSGV. Ingatlah bahwa kami tidak menggunakan Gambar, dan menggantinya dengan Gambarsebagai gantinya, mungkin membuat entri palet tambahan. Aliran operasi T selanjutnya dikompresi sebagai pohon wavelet berbentuk Huffman dengan CHC berkode keras kami. Kami menyimpannya sebagai matriks wavelet [ CNP15 ] dan merujuk ke vektor bit terkonkatenasi level-wise yang dihasilkan sebagai W dan ke indeks awal level di dalam W sebagai W 0 … W 4 . W dibangun dengan algoritma penghitungan awalan [ DEF*21 ]. Di sebelah W kami menyimpan struktur peringkat datar [ Kur22 ] untuk kueri peringkat waktu konstan .
Bit Henti. CSGV memperkenalkan dua varian dari setiap operasi di mana bit henti penanda menentukan apakah wilayah yang dicakup oleh simpul grid konstan di semua level yang lebih halus. Masing-masing simpul di level yang lebih halus kemudian dikecualikan dalam pengodean, sehingga menghasilkan penyimpanan yang mirip dengan Octrees. Kami memisahkan bit henti ini dari kode operasi untuk menjaga ukuran alfabet dan kedalaman pohon wavelet tetap terbatas. Bit henti S [ i ] : i ↦ {0,1} disimpan dalam vektor bit terpisah yang mengikuti setelah daftar operasi dengan struktur data peringkat datarnya sendiri. Kami menerapkan dua varian CSGV-R, dengan dan tanpa menggunakan S .
Header Bata. Header bata menyimpan offset awal setiap LOD CSGV dalam daftar bit operasi dan bit henti sebagai T0 … TL , ukuran palet, dan informasi untuk mengkueri matriks wavelet. Yang terakhir mencakup jumlah bit 1 sebelum setiap level di W sebagai Z1 [0] … Z1 [ 4 ] . Gambar 5 menunjukkan tata letak memori akhir dari bata terkompresi yang tidak sesuai skala. Perhatikan bahwa level pohon wavelet l bukanlah LOD dari grid multiresolusi l dalam pengodean CSGV. Kueri untuk semua LOD CSGV dimulai dalam level pohon wavelet pertama.

3.1. Dekoding Akses Acak
Berikutnya kita bahas perbedaan mendasar dari CSGV akses non-acak dan CSGV-R akses acak kita. CSGV beroperasi secara serial dalam sebuah bata: Untuk mengakses label dari sebuah simpul bata T [ i ], semua simpul sebelumnya T [ j ], j < i harus didekode terlebih dahulu. Dalam praktiknya, bata penuh didekode hingga LOD tertentu dan di-cache, dan jika semua simpul bata akan diakses kemudian, biaya akan cepat diamortisasi. Namun, jika hanya beberapa simpul yang akan diakses, misalnya karena oklusi dalam renderer atau ketika sebuah tugas memerlukan pengambilan sampel voxel acak secara global, cache per bata menimbulkan overhead memori yang signifikan.
Dua alasan utama yang menjadikan dekode serial diperlukan untuk CSGV: Kompresi ANS dengan panjang bit variabel menjadikan pemetaan langsung indeks aliran operasi i ke lokasi memorinya mustahil. Dan tidak ada indeks palet eksplisit yang disimpan Gambardan sebagai gantinya indeks tersebut secara efektif adalah jumlah sebelumnya Gambardalam aliran operasi. Memperoleh operasi ke-i di T adalah kueri akses ( i ) = T [ i ]. Menghitung indeks palet pada operasi i di mana Gambarditerjemahkan menjadi Gambar. Pohon wavelet kami menjawab kedua kueri dalam waktu konstan yang diberikan Σ konstan kami.
Untuk mengatasi referensi induk dan tetangga, CSGV menggunakan informasi sementara yang disimpan dalam bata yang didekode sebagian. Akses acak tidak dimungkinkan karena dekode sebagian tersebut tidak ada dalam kasus ini. Dalam CSGV-R, kami memulai pada simpul grid yang diakses dan mengikuti petunjuk yang diperkenalkan oleh Gambardan Gambarsebagai rantai operasi dari simpul grid ke simpul grid hingga salah satu Gambaratau Gambartercapai (panah merah pada Gambar 3 ). Kemudian, kueri peringkat Gambar mengembalikan indeks ke palet bata tempat label simpul yang diakses dicari.
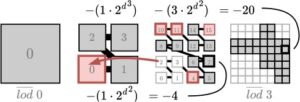
Node grid dapat dirujuk oleh indeksnya di aliran operasi i , atau oleh koordinatnya di grid. Dalam kasus terakhir, koordinat adalah tupel kode Morton 1D node n dari koordinatnya di dalam Gambar. Gambaradalah level paling kasar yang terdiri dari satu node dan L adalah yang paling halus Gambardengan b 3 node. Gambar 4 menunjukkan n di dalam node. Perhatikan bahwa kode Morton dari induk node n adalah ⌊n/2 d ⌋ di mana d = 2 dalam 2D. Operasi node diperoleh sebagai Gambarmengembalikan indeks aliran operasi i untuk tupel (n, l̄ ). idx menghitung offset negatif dari n ke i dalam level yang terjadi karena node sebelumnya dihilangkan oleh bit henti pada level yang lebih kasar (Gambar 4 ). Ingat kembali bahwa vektor bit henti S [ i ] menyimpan untuk setiap node i jika wilayah yang dicakupnya hilang dalam aliran operasi pada semua level yang lebih halus. peringkat S 1 ( i ) mengembalikan jumlah bit 1, yaitu, bit henti, sebelum i di S . Header bata menyimpan indeks aliran dari simpul grid pertama, n = 0, di setiap Gambar, dilambangkan T 0 … T L . Di sini, pemetaan simpul grid ke indeksnya adalah
![]()
di mana P l (n, l̄ ) adalah indeks dari simpul (grand-)parent dari n di Gambar. Meskipun awalnya mungkin tampak bahwa P l memperkenalkan rekursi dengan memerlukan pemetaan indeks operasi itu sendiri, itu dapat dihitung secara iteratif bersama dengan jumlah bagian dalam di Gambarseperti yang ditunjukkan pada Algoritma 1. Karena semua operasi bagian dalam memerlukan waktu yang konstan, Gambardapat dijawab dalam waktu O ( L ) = O (log b ).
Algoritma 2 Operasi Aliran Akses Matriks Wavelet

3.2. Implementasi Pohon Wavelet
Pada GPU, CSGV-R kami adalah buffer dari bata terkompresi yang dirangkai, masing-masing dengan tata letak dari Gambar 5. Alamat perangkat buffer Vulkan memungkinkan untuk meneruskan referensi ke vektor bit bata dan header ke fungsi decoding. Vektor bit dan peringkat datar kami disimpan sebagai array kata 64 bit di mana urutan indeks bit di dalam kata dimulai dari bit paling kecil hingga paling signifikan. Pohon wavelet kami diimplementasikan sebagai matriks wavelet berbentuk Huffman seperti pada Gambar 2 .
Akses Matriks Wavelet. akses W ( i ) dari bit ke- i dalam vektor bit W dihitung sebagai (kata[i / 64] » (i & 63)) & 1 dan menggunakan satu pembagian integer, satu pergeseran bit dan dua bit-bijaksana dan. Pengodean RICE kami seperti CHC (Bagian 3) menghasilkan nomor operasi hanya sebagai jumlah nol sebelum bit 1 pertama dalam simbol pohon wavelet berbentuk Huffman. Selain itu, ini sepenuhnya menghilangkan cabang 1 dan pelacakan interval dimulai dari kueri akses Matriks Wavelet umum [ CNP15 ] seperti yang ditetapkan dalam Algoritma 2.
Algoritma 3 Operasi Stream Wavelet Matrix RankGambar

Peringkat Matriks Wavelet. Kami menggunakan peringkat datar yang diadaptasi [ Kur22 ] untuk kueri peringkat waktu konstan pada vektor bit kami pada overhead ruang 5% (detail dalam suplemen). Peringkat matrik wavelet hanya terjadi untuk . Implementasi peringkatGambar kami runtuh dari bentuk umum (lih. [ CNP15 ]) ke implementasi efisien yang ditunjukkan dalam Algoritma 3: Hardcoding CHC karakter (00001) menghapus semua percabangan. Implementasi matrik wavelet umum harus melacak di mana interval simpul pohon dimulai dalam suatu level [ CNP15 ]. Kami dapat mengoptimalkan semua ini: satu interval ada per level (awalan 0 l ) yang dimulai pada indeks awal level W l di W . Kami membuka loop dalam implementasi kami.
4. Rendering Volume yang Dikodekan CSGV-R
Kami menerapkan perender volume segmentasi menggunakan ray marching dalam shader komputasi Vulkan. Satu utas per piksel berbaris sepanjang sinar dari kamera melalui volume menggunakan traversal penganalisis diferensial digital (DDA) [ AW87 ]. Kami mengakses LOD bata sehingga satu voxel yang didekodekan kira-kira memetakan ke satu piksel dalam gambar keluaran. Untuk LOD yang lebih kasar, ukuran langkah DDA ditingkatkan sesuai dengan itu. Label bata yang diakses dipetakan ke opasitas dan warna oleh fungsi transfer. Nilai opasitas di atas ambang batas ditafsirkan sebagai interaksi permukaan tempat model bayangan difus lokal dievaluasi dan utas tersebut berakhir atau terus mengejar bayangan tidak langsung atau sinar oklusi ambien, tergantung pada mode bayangan.
Bahasa Indonesia: Untuk mengakses label voxel, CSGV menyimpan cache bata yang terlihat, yang sepenuhnya didekode hingga LOD. Ketika perender mereka meminta voxel dari bata yang tidak tersedia, bata tersebut dijadwalkan untuk didekode di bingkai berikutnya; mirip dengan shading atlas streaming [ MVD*18 ] bata ditugaskan ke daerah bebas di cache. CSGV-R kami tidak bergantung pada cache dan perender dapat langsung mengakses voxel dari bata yang dikodekan. Namun, seperti yang dibahas di bagian 5.2, mengoperasikan rendering sepenuhnya dalam domain kompresi lambat dan karenanya hanya boleh digunakan jika anggaran memori ketat. Untuk kasus lain, kami memperkenalkan cache voxel dengan ukuran variabel untuk menyimpan label yang didekode dari voxel tunggal . Ini beroperasi tanpa latensi satu bingkai CSGV karena voxel yang tidak ada dalam cache dapat didekode secara langsung.
4.1. Penyimpanan Voxel
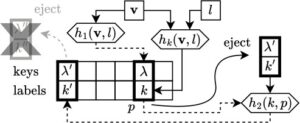
Bahasa Indonesia: Untuk cache voxel opsional kami, kami menggunakan hash map yang menyimpan label λ untuk tuple koordinat voxel v ∈ ℕ 3 (diukur dalam resolusi paling halus) dan LOD yang diminta l . Kami menggunakan hashing Cuckoo [ PR04 ] untuk memetakan tuple ( v , l ) ke posisi dalam hash map p . Hashing Cuckoo mendefinisikan dua fungsi hash untuk setiap elemen, h 1 ( k ) dan h 2 ( k ) yang memetakan kunci elemen k ke posisi dalam dua tabel hash yang berbeda sebagai M 1 ( h 1 ( k )] dan M 2 ( h 2 ( k )]. Karena setiap elemen hanya dapat ditemukan di salah satu dari dua posisi tersebut, fungsi pencarian beroperasi dalam waktu yang konstan. Saat memasukkan elemen, elemen tersebut disimpan di M 1 ( h 1 ( k )]. Bahasa Indonesia: Jika posisi ini sudah ditempati oleh elemen k ′, k ′ dipindahkan ke lokasi kedua M 2 [ h 2 ( k ′)], mungkin mengeluarkan elemen lain yang kemudian dipindahkan dari M 2 ke posisi lainnya di M 1 dan seterusnya (Gambar 6 ). Loop pengeluaran ini berlanjut hingga elemen dimasukkan ke posisi yang tidak ditempati, kedalaman loop yang telah ditentukan tercapai, atau siklus terdeteksi (elemen dimasukkan ke posisi yang ditempati sebelumnya). Untuk membangun fungsi hash, Pagh dan Rodler [ PR04 ] menggunakan kombinasi XOR dari tiga fungsi dari keluarga universal (c,k) [ CW77 ] yang diberikan oleh Dietzfelbinger et al. [ DHKP97 ]:
![]()
di mana a adalah bilangan ganjil dan m adalah bit paling signifikan (MSB) dari ukuran tabel hash pangkat dua. Karena tupel kueri kita berdimensi tiga atau empat, kita memilih keluarga pcg [ O’N14 , JO20 ] sebagai gantinya. Dalam hashing Cuckoo asli [ PR04 ], kunci dalam tabel harus identik dengan tupel akses. Untuk tupel kita ( v , l ) ini akan memerlukan empat bilangan bulat 32 bit. Pagh dan Rodler [ PR04 ] mengusulkan untuk menyimpan kunci yang panjang tersebut di luar tabel dan pointer yang lebih kecil ke kunci di dalam tabel. Berikut ini, kami merinci pendekatan khusus kami yang memungkinkan kami untuk menggunakan hash kecil dari tupel sebagai kunci sebagai gantinya.
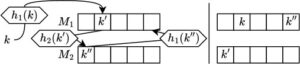
CSGV-R Cuckoo Caching. Kami menggunakan satu tabel tunggal M untuk menampung M 1 dan M 2 pada saat yang sama, seperti yang dibahas oleh Pagh dan Rodler [ PR04 ]. M adalah array yang menyimpan label λ dan kunci 32 bit k untuk mengidentifikasi tabrakan hash di setiap posisi. Fungsi hash pertama untuk metode kami digunakan untuk menentukan posisi pertama dari tupel 4D ( v , l ) di M sebagai

Ketika suatu elemen ( λ,k ) yang dimasukkan pada posisi p mengeluarkan elemen sebelumnya (λ′, k ′) yang p merupakan posisi pertama, elemen yang dikeluarkan tersebut dipindahkan ke posisi kedua p ′. Dengan definisi h̃ 2 kita dapat menghitung p ′ = h2 ( k ′, p ) dengan u = pcg2d ( k ′, p ), mengatur MSB dari k ′ ke 1 dan memasukkan (λ′, k ′) pada p ′. Jika p sudah merupakan posisi kedua untuk (λ′, k ′), maka elemen tidak dapat dipindahkan kembali ke posisi pertamanya karena parameter input untuk h1 tidak tersedia. Sebagai gantinya, elemen dihapus hingga perender mengakses voxel terkait untuk elemen tersebut lagi. Kemudian cache miss akan terjadi dan (λ′, k ′) akan dimasukkan kembali. Perhatikan bahwa elemen masih mengikuti pola hashing Cuckoo yang berganti-ganti antara posisi pertama dan kedua, dan pencarian beroperasi dalam waktu konstan dengan mengakses paling banyak kedua posisi. Kami membatasi rekursi ejeksi ke kedalaman 1 untuk mengakhiri loop ejeksi hashing Cuckoo lebih awal dan dengan demikian membatasi divergensi thread.
4.2. Pencadangan Ruang Kosong
Implementasi naif dari hashing yang dijelaskan di atas akan mengalami kesulitan karena ruang cache dengan cepat terlampaui jika banyak voksel dipetakan ke transparan oleh fungsi transfer. Karena ray marcher tidak dapat menentukan apakah label terlihat sebelum membacanya dari cache atau mendekodenya, solusi lompatan ruang kosong diperlukan untuk mengurangi jumlah voksel yang diakses. Seperti dalam CSGV, kita dapat dengan mudah melewati bata yang tidak berisi label yang terlihat dengan menguji dan menandai palet label di shader lain sebelum merender [ PD24 ]. Namun, ini belum cukup dan dengan demikian kami menambahkan vektor bit lompatan ruang kosong yang lebih halus dan terperinci E yang menyimpan satu bit untuk 2 3 voksel, yang kami sebut sebagai blok kosong , pada LOD terbaik dari volume penuh. Setiap bit dalam E adalah 1 jika dan hanya jika semua voksel di blok kosong itu memiliki label yang tidak terlihat. Untuk blok kosong yang tidak terlihat tersebut, E hanya menyimpan 18 bit per voxel, sedangkan tabel hash M akan memerlukan 64 bit per voxel yang tidak terlihat (32 untuk λ dan 32 untuk k ). Perhatikan bahwa untuk blok kosong yang terlihat sebagian, semua voxelnya harus didekodekan dan disimpan dalam cache di M .
Kami mengkonstruksi E on-the-fly selama rendering: Ia diinisialisasi ke E = (000… 000) 2 dan direset setiap kali fungsi transfer visibilitas berubah. Algoritme 4 berisi metode akses voxel kami, termasuk penanganan vektor bit ruang kosong opsional E dalam warna abu-abu. Menyatukan semuanya: kami mendekode voxel ( v , l ) jika v tidak berada di dalam bata yang sama sekali tidak terlihat yang belum ditandai sebagai kosong di E , dan tidak disimpan dalam peta hash label M . Ketika voxel yang baru didekode tersebut tidak terlihat, semua voxel yang berbagi blok kosongnya juga didekode. Ini dilakukan pada LOD terbaik terlepas dari l . Jika tidak ada yang terlihat, blok kosong ditandai tidak terlihat di E untuk akses selanjutnya. Jika tidak, M digunakan untuk menyimpan label ( v , l ) seperti sebelumnya.
Algoritma 4 getLabelOfVoxel(uvec3 v , uint l ). Kami menggunakan varian hashing Cuckoo untuk penyimpanan label voxel dan vektor bit penghilang ruang kosong opsional (abu-abu). Penyisipan dalam E dan M bersifat atomik.

5. Evaluasi
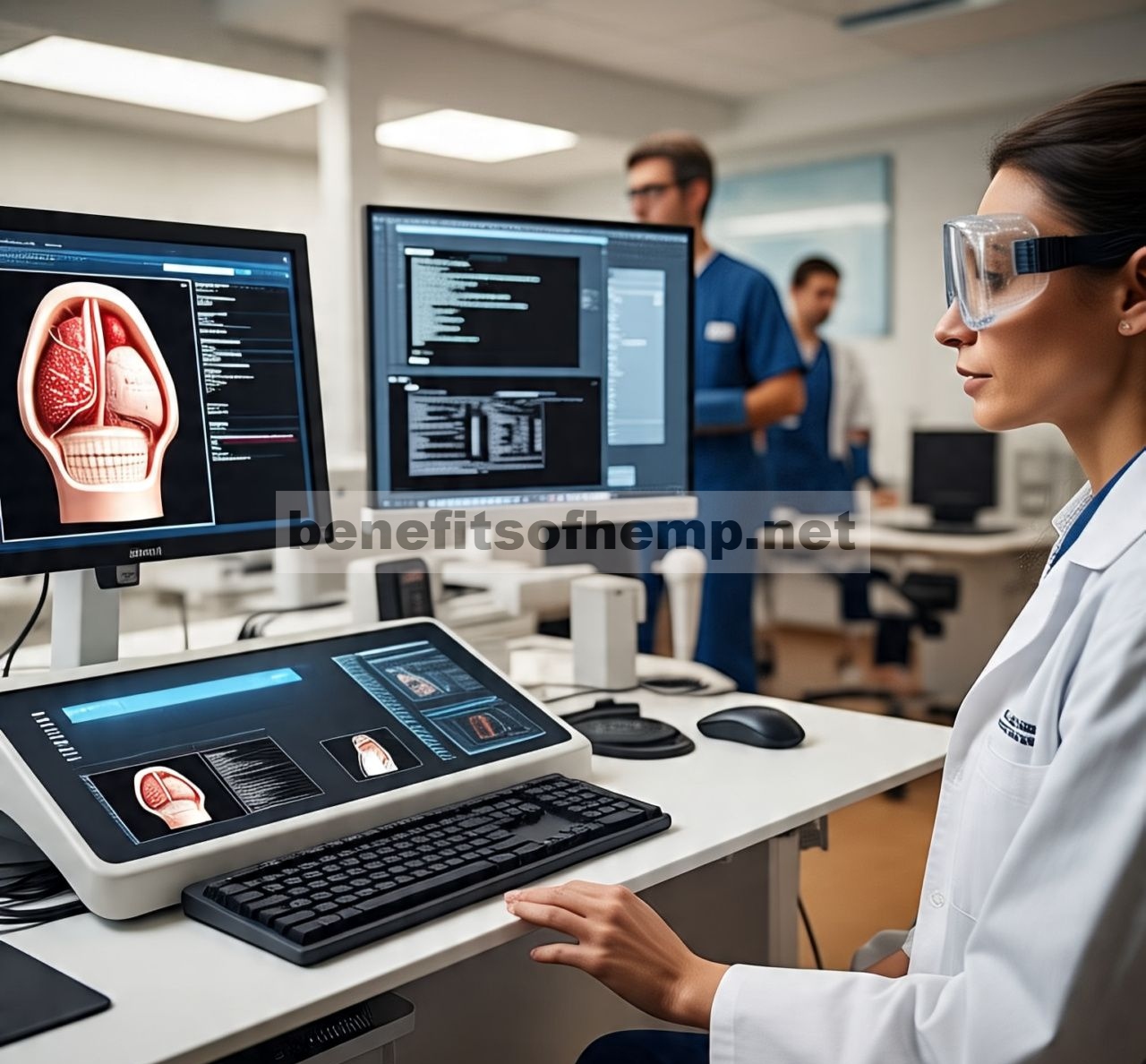
Kami mengevaluasi penerapan metode kami pada sistem yang menggunakan CPU AMD Ryzen 7 5800x 8-core dengan RAM 64GB dan GPU RTX 4070 TI Super dengan VRAM 16GB pada kecepatan clock GPU tetap. Kami akan merilis kode sumber kompresi CSGV-R kami. Kumpulan data evaluasi ditunjukkan pada Gambar 1 dan tercantum dalam Tabel 1 :
- Serat [ MSJ*22 ] adalah hasil pemindaian sinar-X dari polimer yang diperkuat serat dengan contoh serat kaca tersegmentasi. Daerah yang memanjang membentang di beberapa bata dan menciptakan visibilitas parsial yang kompleks selama rendering.
- H01 adalah bagian besar dari fragmen petavoxel H01 dari korteks serebral manusia [ SCJB*24 ]. Ini adalah contoh khas volume konektomik dengan struktur berlabel yang lebih besar namun kompleks dan saling terkait, serta dimensi volume yang luas.
- AZBA [ KSY*21 ] adalah otak ikan zebra yang tersegmentasi penuh dengan karakteristik yang umum terlihat dalam kumpulan data medis: jumlah daerah berlabel yang lebih sedikit dengan variasi ukuran yang tinggi. Kami merendernya dengan area semi-transparan yang besar yang menciptakan beban akses voxel yang tinggi.
Tabel 1. Dimensi dan ukuran volume segmentasi yang dievaluasi. Byte per voxel dalam volume yang tidak terkompresi diberikan dalam (). Kumpulan Data Voxel (Bahasa Indonesia: Voxel) Label Ukuran Asli [GB] Sel Ukuran 1000×1000×1000 1.067.196 orang 4.000 (4B) serat Ukuran 1579×1092×1651 26.372 orang 5.694 (2B) H01 Ukuran: 5120×6144×6144 1.296.889 773.094 (4B) Bahasa Indonesia: AZBA Ukuran 470×1224×670 204 0,385 (1B)
5.1. Tingkat Kompresi
Meja 2 menunjukkan hasil kompresi CSGV-R kami dalam konfigurasi berbeda dan perbandingan dengan CSGV. b yang lebih besar meningkatkan rasio kompresi untuk keduanya, yang disebabkan oleh pengodean yang lebih mahal pada batas bata dan label duplikat dalam palet. Saat tidak menggunakan pengodean panjang bit variabel apa pun, aliran operasi mengodekan volume untuk ukuran bata b = 64 dengan rasio kompresi antara 6,4% dan 1% (CSGV Nibble). Dengan pengodean panjang bit variabel ANS akses non-acak, rasio yang ditingkatkan berada di antara 2,8% dan 0,4%, dan mendekati entropi (CSGV rANS). Kompresi matriks wavelet akses acak kami (CSGV-R+bit henti) menghasilkan kompresi antara 4,4% dan 0,6%. ANS mencapai kompresi yang lebih baik karena pengodean bit fraksionalnya dapat mengikuti frekuensi simbol relatif lebih dekat. Kode Huffman kami mengodekan operasi hanya dengan bilangan bulat bit. Lebih jauh, CSGV mengodekan kombinasi bit henti dan kode operasi dalam satu simbol gabungan sementara kami menyimpan bit henti dalam vektor bit terpisah untuk membatasi kedalaman pohon wavelet, dan dengan demikian membatasi waktu kueri. Mengodekan aliran operasi sebagai matriks wavelet secara komputasi lebih mahal daripada dengan ANS dan menghasilkan waktu kompresi yang lebih lama. Dengan bit henti, lebih sedikit simpul bata yang ada dan harus dikompresi secara total yang meningkatkan pengaturan waktu.
| Gigitan CSGV | CSGV menang | CSGV-R | CSGV-R + bit penghenti | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | Bahasa Inggris | Waktu (s) | GB/detik | Bahasa Inggris | Waktu (s) | GB/detik | Bahasa Inggris | Waktu (s) | GB/detik | Bahasa Inggris | Waktu (s) | GB/detik | |
| C | 16 | 6,833% | 2.376 | 1.684 | 3,436% | 2.016 | 1.984 | 6,111% | 3.47 | 1.153 | 5,528% | 2.549 | 1.569 |
| 32 | 6,561% | 1.773 | 2.256 | 2,996% | 1.781 | 2.246 | 5,489% | 3.211 | 1.246 | 4,653% | 2.308 | 1.733 | |
| 64 | 6,425% | 2.473 | 1.618 | 2,802% | 2.412 | 1.658 | 5,257% | 3.858 | 1.037 | 4,411% | 2.919 | 1.37 | |
| F | 16 | 2,97% | 3.401 | 1.674 | 1,488% | 3.95 | 1.442 | 9,031% | 8.514 | 0,669 tahun | 2,899% | 4.018 | 1.417 |
| 32 | 2,558% | 2.464 | 2.311 | 0,979% | 2.585 | 2.202 | 8,299% | 7.539 | 0,755 tahun | 1,759% | 2.896 | 1.966 | |
| 64 | 2,496% | 3.883 | 1.466 | 0,894% | 3.978 | 1.431 | 8,379% | 9.299 | 0.612 | 1,593% | 4.338 | 1.313 | |
| H01 | 16 | 2,83% | 276.978 | 2.791 | 1,616% | 283.78 | 2.724 | 5,005% | 594.828 | 1.3 | 2,644% | 348.655 | 2.217 |
| 32 | 2,608% | Nomor 228.101 | 3.389 | 1,361% | 231.258 | 3.343 | 4,449% | 539.476 | 1.433 | 2,005% | 279.779 | 2.763 | |
| 64 | 2,566% | 312.467 | 2.474 | 1,31% | 307.957 | 2.51 | 4,336% | 619.911 | 1.247 | 1,882% | 345.899 | 2.235 | |
| Bahasa Indonesia: AZBA | 16 | 1,871% | 0,349 tahun | 1.103 | 1,399% | 0.703 | 0,548 tahun | 17,656% | 1.124 | 0.343 | 3,314% | 0,376 tahun | 1.024 |
| 32 | 1,079% | 0,279 tahun | 1.383 | 0,495% | 7.532 | 0,051 tahun | 16,061% | 1.023 | 0,377 tahun | 0,958% | 0.292 | 1.319 | |
| 64 | 0,968% | 0.47 | 0.821 | 0,366% | 0,984 | 0.392 | 18,1% | 1.431 | 0.269 | 0,648% | 0.469 | 0.822 | |
Perbandingan dengan kompresor volume segmentasi lain ditunjukkan dalam (Tabel 3 ). Kompresor tujuan umum seperti gzip yang digunakan dalam format hdf5 [ HDF ] mencapai hasil kompresi di bawah standar. Compresso mencapai kompresi yang kuat saat dipasangkan dengan LZMA global tetapi akses acak tidak memungkinkan. CSGV [ PD24 ] mencapai kompresi yang kuat dan setidaknya mendukung akses acak ke bata, namun, akses voxel acak atau kueri domain kompresi tidak didukung. Karena paletting bata-bijaksananya yang sederhana, Neuroglancer [ Goo16 ] adalah format cepat dengan akses acak hingga ke tingkat voxel; namun, laju kompresinya adalah yang terburuk dari semua metode yang dievaluasi. CSGV-R kami dengan vektor bit henti mencapai laju kompresi yang kira-kira dua kali lipat dari laju CSGV, tetapi masih jauh lebih baik daripada Neuroglancer, satu-satunya format akses acak sejati lainnya. Dalam beberapa set data, misalnya AZBA dan F iber , CSGV-R kami bahkan mengungguli Compresso dengan LZMA.
| kumpulan data | ukuran/#label | hdf5 | Kompresor | + LZMA | Neuroglancer | CSGV menang | CSGV-R | +bit berhenti |
|---|---|---|---|---|---|---|---|---|
| C | 4,0 GB | 7,221% | 8,337% | 2,753% | 13,622% | 2,802% | 5,257% | 4,411% |
| Label 1 juta | 21,8 detik | 33,0 detik | 138,5 detik | 10,8 detik | 15,9 detik | 25,5 detik | 17,7 detik | |
| F | 5,7 GB | 3,051% | 26,70% | 5,861% | 3,658% | 0,892% | 8,379% | 1,593% |
| label 26K | 47,4 detik | 139,2 detik | 654,1 detik | 11,0 detik | 19,4 detik | 61,8 detik | 18,4 detik | |
| H01* | 4,295 GB | 3,678% | 2,284% | 0,342% | 3,882% | 1,273% | 4,313% | 1,830% |
| 5,7 ribu label | 18,0 detik | 19,6 detik | 53,4 detik | 6,3 detik | 9,0 detik | 23.0 detik | 9,2 detik | |
| Bahasa Indonesia: AZBA | 0,385 GB | 2,166% | 88,357% | 1,901% | 2,801% | 0,366% | 18.100% | 0,648% |
| 204 label | 7,0 detik | 9,0 detik | 47,2 detik | 1,2 detik | 2,3 detik | 9,1 detik | 1,9 detik |
5.2. Rendering
Kami mengevaluasi akses acak CSGV-R kami dalam perender berbaris sinar DDA dengan berbagai konfigurasi. Dalam Tabel 4 Kami mencantumkan waktu render rata-rata per bingkai yang diukur untuk jalur kamera di sekitar set data dan membandingkannya dengan CSGV. Kami menggunakan b = 32 kecuali untuk H01 di mana b = 64. Saat menggunakan cache selama rendering, ukuran cache adalah 1 GiB kecuali saat merender H01 dengan CSGV di mana cache yang lebih besar diperlukan yang kami pilih 4 GiB. Untuk sinar bayangan dan oklusi ambien, kami mentransmisikan satu sinar tidak langsung per piksel per bingkai. Rendering dengan CSGV-R umumnya mengungguli decoding brick-serial CSGV, antara lain dengan tidak memerlukan caching terpisah [ MVD*18 ] dan tahap shader decoding ( tanpa cache atau cache voxel ) yang juga mengurangi kompleksitas implementasi. Lebih jauh, ini mengurangi jumlah voxel yang didekode secara tidak perlu dan mencapai koherensi thread yang lebih tinggi selama decoding. Meskipun penggunaan bit henti meningkatkan rasio kompresi, permintaan tambahan vektor bit henti untuk perhitungan indeks aliran operasi membebani kinerja decoding. Khususnya untuk set data seperti Cells , di mana daerah label kecil dan sedikit bit henti yang ditetapkan, waktu bingkai hampir dua kali lipat. Berbagai mode caching dan decoding dibahas di bawah ini
| naungan lokal | sinar bayangan | oklusi ambien | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | F | H01 | Bahasa Indonesia: AZBA | C | F | H01 | Bahasa Indonesia: AZBA | C | F | H01 | Bahasa Indonesia: AZBA | ||
| CSGV menang | tempat penyimpanan batu bata | 11.8 | 6.0 | 4.1 | 10.3 | 13.1 | 7.8 | 4.2 | 12.4 | 18.1 | 9.2 | 4.8 | 17.2 |
| CSGV-R tidak ada bit henti | tidak ada cache | 25.3 | 7.6 | – | 19.2 | 32.9 | 12.7 | – | 25.0 | 37.4 | 15.4 | – | 31.1 |
| cache voxel | 10.1 | 6.4 | – | 9.3 | 12.8 | 9.2 | – | 11.6 | 13.2 | 11.9 | – | 13.3 | |
| cache voxel (es) | 5.4 | 5.8 | – | 7.9 | 6.7 | 8.1 | – | 10.0 | 8.1 | 10.7 | – | 12.2 | |
| batu bata c cache (sm) | 8.1 | 4.5 | – | 9.3 | 9.4 | 6.4 | – | 11.2 | 11.3 | 7.4 | – | 13.9 | |
| CSGV-R+sb | tidak ada cache | 44.9 | 12.8 | 6.5 | 28.6 | 59.5 | 22.5 | 8.6 | 37.9 | 70.4 | 29.6 | 14.1 | 47.2 |
| cache voxel | 9.7 | 6.3 | 1.2 | 8.8 | 12.4 | 9.0 | 1.3 | 10.9 | 13.2 | 11.9 | 1.8 | 13.0 | |
| cache voxel (es) | 6.1 | 7.1 | 75.8 | 8.1 | 7.6 | 9.9 | 79.9 | 10.2 | 9.4 | 13.3 | 109.1 | 12.6 | |
| batu bata c cache (sm) | 11.0 | 5.6 | 22.4 | 10.9 | 12.3 | 7.3 | 22.6 | 12.9 | 14.6 | 8.4 | 23.6 | 16.3 | |
Dekompresi Akses Acak. Karena kompresi CSGV-R kami menawarkan akses acak yang sebenarnya, kami dapat melakukan rendering tanpa cache apa pun ( tanpa cache ). Namun, akses voxel tersebut memiliki konsekuensi: mengejar operasi hingga operasi palet, melintasi matriks wavelet untuk setiap akses ini serta kueri peringkat indeks palet akhir . Akibatnya, caching voxel individual yang didekode ( cache voxel ) dengan tabel hash voxel dan hashing Cuckoo khusus (Bagian 4.1) secara signifikan meningkatkan kinerja, dalam beberapa kasus hingga faktor 5. Karena sebagian besar sel cache voxel berisi label tak terlihat, kami memperkenalkan vektor bit ruang kosong opsional yang kami isi saat itu juga selama rendering ( cache voxel (es) ). Sementara ini meningkatkan waktu render untuk Sel dan AZBA, kami mengukur perubahan minimal untuk Serat , dan kinerja bahkan menurun secara signifikan untuk H01. Ini mungkin karena dimensi besar H01 yang menghasilkan banyak pembacaan memori jauh dalam vektor bit ruang kosong yang lebih panjang. Selain itu, pengaturan tanda bit ruang kosong memerlukan kueri 2 3 voxel dalam LOD paling halus dan paling mahal, sementara akses umum dalam H01 biasanya ke LOD yang lebih kasar dan lebih cepat diakses.
Tahap Dekompresi Berdasarkan Bata. CSGV hanya mendukung caching bata penuh [ PD24 ], didekompresi oleh shader terpisah hingga LOD yang diminta dengan latensi satu bingkai ( cache bata ). Wilayah cache untuk bata dalam LOD yang diminta ditetapkan seperti dalam shading atlas streaming [ MVD*18 ]. Shader decoding harus mendekompresi bata secara serial menggunakan satu utas per bata, yaitu setiap utas dalam wavefront GPU mengakses wilayah memori global yang berbeda dan beban kerja yang berbeda yang menyebabkan divergensi utas. Kami menerapkan tahap shader dekompresi berdasarkan bata alternatif untuk CSGV-R kami di mana satu wavefront secara kooperatif mendekompresi satu bata untuk mode CSGV-R): Utas dalam wavefront mengulangi voxel keluaran dalam LOD yang diminta dan membaca label volumenya dengan akses acak seperti biasa. Untuk lebih meningkatkan kinerja, pohon wavelet bata disalin ke memori bersama sebelum decoding ( cache bata c (sm) ). Untuk Fiber , decoding kooperatif dari batu bata ini menghasilkan rendering yang paling cepat.
5.3. Overhead dan Latensi Caching CSGV
Sementara CSGV mencapai volume terkompresi yang lebih kecil, ia selalu memerlukan memori ekstra selama rendering untuk cache bata yang terlihat. Volume yang dikodekan CSGV-R tidak memiliki overhead ini dan dapat dirender selama mereka cocok dengan VRAM. Pertama kali bata di CSGV diakses, bata itu tidak ada dalam cache. Sebelum didekompresi, sampel acak dari palet bata atau label yang paling sering di bata (entri palet pertama) dapat digunakan sebagai placeholder. Namun, ini menghasilkan artefak popping yang terlihat (Gambar 8 ). Dalam kasus terburuk, cache tidak cukup besar untuk menyimpan semua bata yang diakses saat merender bingkai. Faktanya, cache CSGV hampir tidak cocok untuk semua bata untuk konfigurasi oklusi ambien. Traversal yang lebih dalam seperti dalam penelusuran jalur tidak akan memungkinkan decoding semua voksel yang terlihat di CSGV. Dalam kasus apa pun, terutama saat mentransmisikan sinar tidak langsung untuk oklusi ambien, latensi setidaknya satu bingkai mengurangi jumlah sampel yang dirender yang valid per bingkai. CSGV-R tanpa cache atau voxel caching menghasilkan gambar bebas artefak pada frame pertama. Karena akses voxel langsung selalu tersedia, cache voxel tidak harus sesuai dengan semua area yang terlihat dan oleh karena itu ukurannya dapat dipilih secara bebas.
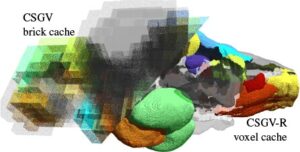
6. Kesimpulan
Kami menyajikan akses acak penuh dan kompresi lossless untuk volume segmentasi yang mengungguli state-of-the-art terkini dengan akses acak dalam hal tingkat kompresi. Pada saat yang sama, kinerja kuerinya yang tinggi membuatnya cocok untuk pemrosesan berbasis GPU seperti dalam rendering. Representasi CSGV-R kami memungkinkan berbagai skema akses voxel sementara metode CSGV terbatas pada brick caching yang juga kami ungguli. Metode kami menghilangkan artefak rendering dari CSGV sambil meningkatkan kinerja render dengan faktor hingga 5 dan memungkinkan kami untuk merender volume segmentasi dengan lebih dari satu juta label dan ukuran hingga 770 GB pada sistem konsumen. Keterbatasan CSGV-R adalah tingkat kompresi yang lebih lemah: sementara tidak semua area dapat didekodekan sekaligus, CSGV setidaknya memasukkan volume yang lebih besar ke dalam memori GPU. b yang lebih besar menurunkan kinerja secara tidak proporsional di CSGV-R karena hierarki LOD yang lebih dalam dilintasi per voxel. CSGV tetap lebih disukai untuk penyimpanan dan pemrosesan serial. Secara lebih umum, kami telah menunjukkan bagaimana pohon wavelet dapat dimanfaatkan sebagai kompresi panjang bit variabel akses acak dalam tugas rendering berkinerja tinggi dan bagaimana pohon wavelet dapat dioptimalkan untuk kueri yang lebih cepat dengan pengetahuan domain. Dalam pekerjaan mendatang, kami ingin mengeksplorasi cara untuk lebih meningkatkan laju kompresi volume CSGV-R kami, misalnya melalui metode dari kompresi vektor bit, sambil mempertahankan kinerja rendering dengan penghilangan ruang kosong multiresolusi dan penyimpanan sementara yang lebih adaptif.