ABSTRAK
Pengujian mutasi telah berhasil diterapkan pada beberapa bahasa pemrograman. Meskipun bermanfaat untuk pengujian perangkat lunak, biaya komputasinya yang tinggi telah mencegahnya digunakan secara luas. Beberapa penyempurnaan telah diusulkan untuk mengurangi biayanya dengan mengurangi jumlah mutan yang dihasilkan, salah satunya adalah Pengujian Mutasi Evolusioner. Penyempurnaan ini bertujuan untuk menghasilkan sekumpulan mutan yang lebih sedikit dengan Algoritma Evolusioner, yang mencari mutan yang berpotensi setara dan sulit dibunuh yang membantu meningkatkan rangkaian pengujian. Studi ini menyajikan Tempus , sebuah sistem yang mencakup versi pembuatan individu Berbasis Profil dari Pengujian Mutasi Evolusioner. Tempus telah diterapkan pada empat studi kasus yang memproses informasi secara real time dari sistem Internet of Things. Volume informasi yang sangat besar ini datang sebagai peristiwa yang perlu dipantau dan diproses secara real time: studi kasus mengelola peristiwa melalui kueri Bahasa Pemrosesan Peristiwa Esper . Mengingat bahwa peristiwa yang digunakan sebagai input dalam sistem Internet of Things mungkin memerlukan reaksi dalam periode waktu tertentu, sangat penting untuk menguji bahwa sistem dapat memicu respons yang diharapkan sesuai permintaan dalam periode yang diharapkan. Setelah menerapkan Tempus pada rangkaian pengujian kami, 62 dari 80 percobaan menunjukkan pengurangan biaya dibandingkan Pengujian Mutasi Evolusioner.
1 Pendahuluan
Pengujian mutasi adalah teknik pengujian berbasis kesalahan yang dapat mengukur efektivitas rangkaian pengujian, yaitu seberapa baik rangkaian tersebut dapat mendeteksi kesalahan (definisi oleh DeMillo et al. [ 1 ]). Teknik ini memperkenalkan perubahan sintaksis kecil dalam program yang diuji dengan menerapkan operator mutasi untuk menghasilkan program yang salah yang disebut mutan . Dengan menerapkan teknik ini, kita dapat mensimulasikan banyak kesalahan yang dibuat oleh programmer dan mencegah aplikasi membuat keputusan yang salah.
Menurut Offutt dan Untch [ 2 ], kelemahan utama pengujian mutasi adalah biayanya: dibutuhkan waktu untuk menjalankan banyak mutan yang diproduksi untuk beberapa program terhadap rangkaian pengujiannya. Beberapa penyempurnaan telah diusulkan untuk mengurangi biaya pengujian mutasi dengan mengurangi jumlah mutan yang dihasilkan. Evolutionary Mutation Testing ( EMT ), diusulkan oleh Domínguez-Jiménez et al. [ 3 ] memilih sekumpulan mutan yang dikurangi melalui Evolutionary Algorithm ( EA ), yang mencari mutan yang berpotensi setara dan sulit dibunuh, yang didefinisikan sebagai mutan yang kuat, untuk membantu meningkatkan rangkaian pengujian.
Domínguez-Jiménez et al. [ 3 ] menunjukkan bahwa EMT telah efektif dengan komposisi layanan web WS-BPEL dan Delgado-Pérez et al. [ 4 ] melakukan hal yang sama dengan program C++ berorientasi objek. Mengingat IoT menjadi semakin penting di seluruh dunia, karya ini menerapkan EMT ke program IoT sebagai studi kasus. Pengujian IoT berkaitan dengan keamanan dan kinerja: jika sistem IoT diuji sebelum diluncurkan, kami akan dapat mendeteksi kesalahan dan mencegah kemungkinan kegagalan krichen [ 5 ]. Kelemahannya adalah bahwa pengujian sistem waktu nyata, seperti yang dijelaskan oleh Heath [ 6 ], adalah aktivitas yang kompleks dan memakan waktu. Persyaratan waktu nyata seperti ketepatan waktu, simultanitas, dan prediktabilitas membuat pengujian menjadi mahal.
Banyak sistem IoT menggunakan keluarga bahasa tertentu untuk memproses dan memantau peristiwa yang masuk: yaitu, Bahasa Pemrosesan Peristiwa (EPL). Kami telah memilih EPL sumber terbuka yang dibuat oleh EsperTech [ 7 ] untuk mesin Esper-nya (Esper EPL mulai sekarang). Seperti kebanyakan EPL, Esper EPL bekerja melalui aliran peristiwa.
MuEPL adalah alat uji mutasi untuk Esper EPL yang dikembangkan oleh Gutiérrez-Madroñal et al. [ 8 ], dan GAmera , dibuat oleh Domínguez-Jiménez et al. [ 9 ], mengimplementasikan versi pertama EMT menggunakan EA . Untuk menerapkan EMT ke Esper EPL, jembatan untuk menghubungkan sistem mutasi MuEPL dan GAmera telah dikembangkan. Jembatan ini dikenal sebagai Tempus ; sistem tempat EMT diterapkan ke bahasa pemrograman Esper EPL, tidak hanya dengan implementasi aslinya tetapi juga menggunakan pendekatan mutasi terpandu (Guided EMT ) yang terinspirasi oleh karya Zhang et al. [ 10 ]. Gutiérrez-Madroñal et al. [ 11 ] memperkenalkan Guided EMT karena hasilnya tidak menunjukkan EMT menjadi pemenang yang konsisten atas pemilihan acak dalam studi kasus. Mengingat bahwa EMT bekerja dengan baik dengan WS-BPEL dan C++, penulis menyimpulkan bahwa mutan kuat dalam kueri Esper EPL didistribusikan secara berbeda dari program WS-BPEL/C++, yang menyebabkan masalah dengan pembuatan individu baru dan operator mutasi genetik. Masalah ini mendorong beberapa penyempurnaan dalam EMT untuk lebih memandu pencarian dan perbandingan hasil. Meskipun hasil positif diperoleh dengan modifikasi, hasil menunjukkan bahwa fungsi kebugaran EMT perlu lebih bernuansa.
Dalam makalah ini, kami menunjukkan manfaat mengintegrasikan EMT dengan dua penyempurnaan berbeda yang lebih baik dalam menangani kasus-kasus di mana sebagian besar mutan kuat. Kontribusi terpenting dari makalah ini adalah sebagai berikut:
- Memperluas EMT dengan sumber informasi baru: cakupan pengujian dan profil operator . Gutiérrez-Madroñal dkk. [ 11 ] mengungkapkan hasil yang menunjukkan bahwa EMT memerlukan informasi lebih banyak untuk menemukan mutan yang kuat dengan cepat. Dalam makalah ini, EMT diperluas dengan beberapa fitur baru yang dimaksudkan untuk memandu pencarian dengan informasi tambahan. Beberapa informasi ini berasal dari studi lebih lanjut tentang hasil eksekusi, dan beberapa diekstraksi dari aplikasi pengujian mutasi sebelumnya ke program lain dalam bahasa yang sama. Peningkatan ini melibatkan perubahan berikut:
- Pengukuran cakupan dalam kueri Esper EPL . Teori pengujian mutasi menunjukkan bahwa untuk membunuh mutan, kasus uji harus memenuhi tiga kondisi: mencapai mutasi, menyebabkan perubahan dalam status internal (kesalahan), dan menyebarkan perubahan tersebut ke perilaku yang dapat diamati (menyebabkan kegagalan pengujian). Kami telah memperluas MuEPL untuk mendeteksi apakah eksekusi program mencapai mutan.
- Fungsi kebugaran yang Mengetahui Cakupan . Berdasarkan kontribusi sebelumnya, EMT telah ditingkatkan dengan memperluas matriks kebugaran untuk mempertimbangkan mutasi yang hidup dan yang tercakup. EMT dapat dikonfigurasi untuk mendukung atau menghukum kasus-kasus ini. Ini akan memungkinkan untuk memilih di antara pasangan individu yang sebelumnya memiliki nilai kebugaran yang identik, dan akan memandu pencarian EA dengan lebih baik .
- Pembuatan individu baru berbasis profil . Karya ini menyajikan Pembuatan individu berbasis profil ( PBig ), varian baru EMT yang menghasilkan individu baru berdasarkan pengetahuan sebelumnya dari program lain tentang operator mana yang lebih mungkin menghasilkan mutan yang kuat . Hal ini memungkinkan EA yang tidak bergantung pada bahasa untuk mempertimbangkan informasi tentang sifat operator mutasi untuk bahasa pemrograman tertentu. Kami berhipotesis bahwa fitur tertentu dari suatu bahasa mungkin lebih sulit diuji secara efektif daripada yang lain, sehingga operator mutasi terkaitnya lebih mungkin menghasilkan mutan yang kuat.
- Tempus , sistem yang mengimplementasikan ekstensi yang diusulkan untuk EMT dan menerapkannya pada Esper EPL.
Sisa dari makalah ini disusun sebagai berikut. Di Bagian 2 , latar belakang penelitian kami dirinci. Bagian 3 menjelaskan bagaimana Tempus diimplementasikan. Bagian 4 menyatakan pertanyaan penelitian dan desain eksperimen kami. Bagian 5 menjawab pertanyaan melalui analisis hasil. Bagian 3 mengulas pekerjaan terkait. Bagian terakhir menyajikan kesimpulan dan lini penelitian kami di masa mendatang.
2 Latar Belakang
2.1 Bahasa Pemrosesan Peristiwa Esper
IoT menghubungkan objek dan sistem, yang berbagi informasi dalam bentuk peristiwa. Peristiwa ini harus disaring dan diproses untuk membuat keputusan yang tepat dalam situasi mendesak. Misalnya, sensor yang melaporkan dua nilai suhu berturut-turut lebih besar dari 400 (seperti dalam Contoh 1 ) dapat berarti ada kebakaran. Namun, sistem tidak akan memicu alarm jika aturan atau pola yang digunakan untuk mengidentifikasinya memiliki kesalahan. Jika sistem IoT berfungsi, alarm dapat memperingatkan petugas pemadam kebakaran dan orang-orang di sekitar area. Selain itu, dapat mengaktifkan sistem proteksi kebakaran. Ini akan membantu memadamkan api, mengurangi waktu tindakan dan membantu menjaga orang tetap aman. Vijayalakshmi dan Muruganand [ 12 ] menjelaskan cara mendeteksi kebakaran melalui sistem IoT. Dengan cara yang sama, gagal menafsirkan dengan benar nilai yang dikirim oleh alat pacu jantung karena pola atau aturan yang salah yang dimaksudkan untuk mengidentifikasi serangan jantung dapat mengakibatkan hilangnya nyawa. Sistem yang benar dapat memperingatkan tim medis atau memanggil ambulans dan bertindak cepat untuk menyelamatkan orang tersebut. Sistem IoT untuk mendeteksi serangan jantung diusulkan oleh Chao [ 13 ].
Contoh 1. Kueri Exper EPL untuk mendeteksi kenaikan suhu.
Pertanyaan Esper EPL:
Pilih A sebagai temp1, B sebagai temp 2 dari
pola [setiap temp1.temperature > 400 -> temp2.temperature > 400]
Etzion dan Niblett [ 14 ] mendefinisikan agen pemrosesan peristiwa sebagai modul perangkat lunak yang memproses peristiwa, yang ditentukan menggunakan EPL. Keempat studi kasus di Bagian 2.6 menggunakan Esper EPL dari EsperTech [ 7 ], yang berorientasi aliran dan memiliki sintaksis yang sangat mirip dengan SQL. Bahasa pemrograman kueri ini digunakan untuk mengilustrasikan contoh-contoh di subbagian latar belakang berikut.
2.2 Pengujian Mutasi
Pengujian mutasi merupakan teknik berbasis kesalahan yang sudah dikenal luas yang telah digunakan untuk mengevaluasi dan meningkatkan kualitas rangkaian pengujian otomatis. Pengujian mutasi menghasilkan variasi sintaksis atau mutan dari program asli dengan menerapkan operator mutasi . Setiap operator mutasi mewakili kesalahan pemrograman ‘umum’ yang dibuat oleh pengembang.
Pengujian mutasi telah diterapkan ke berbagai domain karena teknologi baru telah muncul. Misalnya, Klampfl et al. [ 15 ] menerapkan pengujian mutasi ke jaringan saraf tiruan, Strug dan Strug [ 16 ] berbicara tentang pembelajaran mesin dan pengujian mutasi, Ma et al. [ 17 ] mengusulkan kerangka pengujian yang khusus dalam sistem pembelajaran mendalam dan Gutiérrez-Madroñal et al. [ 18 ] menerapkan pengujian mutasi ke bahasa kueri Google. Mengingat popularitas sistem waktu nyata, fitur bahasa pemrograman tradisional telah diperluas untuk digunakan dengan sistem waktu nyata. Meskipun ada berbagai penelitian tentang bahasa pemrograman tradisional, seperti Java, C dan Ada (Ma et al. [ 19 ]; Agrawal et al. [ 20 ]; Offutt et al. [ 21 ]), beberapa dari penelitian ini belum diperbarui ke versi bahasa ini yang lebih baru. Survei oleh Papadakis et al. [ 22 ] pada keseluruhan status pengujian mutasi mencantumkan banyak sistem mutasi, tetapi tidak ada yang terkait dengan Esper EPL. Gutiérrez-Madroñal et al. [ 23 ] menyajikan aplikasi awal pengujian mutasi pada Esper EPL, mendefinisikan dan mengimplementasikan serangkaian operator mutasi setelah menganalisis lebih dari 3700 kueri dalam proyek nyata: klasifikasi lengkap 1 disajikan dalam tesis Gutiérrez-Madroñal et al. [ 24 ]. Ini terdiri dari 34 operator mutasi di empat kategori, tergantung pada jenis elemen yang terkait dengannya. Beberapa operator khusus untuk Esper EPL, sementara yang lain diadaptasi dari bahasa lain, terutama dari SQL.
Penerapan analisis mutasi secara otomatis pada program yang ditulis dalam bahasa pemrograman tertentu memerlukan alat untuk menghasilkan mutan, menjalankannya dalam kasus uji, dan memutuskan apakah mutan telah dibunuh atau tidak dengan membandingkan perilakunya dengan program asli untuk setiap kasus uji. Untuk menerapkan pengujian mutasi pada Esper EPL, sistem mutasi MuEPL 2 dikembangkan dan disajikan dalam karya kami sebelumnya Gutiérrez-Madroñal et al. [ 8 ]. Gambar 1 menguraikan komponen utama MuEPL dan bagaimana mereka saling berbagi informasi.
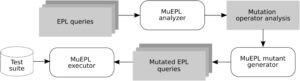
Gutiérrez-Madroñal et al. (2019) mendefinisikan program sebagai sekumpulan kueri EPL. Sekumpulan kueri EPL dari program yang diuji diperiksa oleh komponen penganalisa MuEPL , yang mengeluarkan daftar operator mutasi yang dapat diterapkan. Misalnya, keluaran MuEPL setelah menganalisis kueri EPL Contoh 1 adalah daftar operator mutasi yang dapat diterapkan. Salah satu operator mutasi ini adalah operator mutan ROR (Relational Operator Replacement), yang dapat diterapkan di 2 lokasi. Menurut sintaksis Esper EPL, setiap operator relasional dapat digantikan oleh 5 operator relasional lainnya (lihat atribut ROR dalam Tabel 1 ). Setelah analisis, komponen generator mutan MuEPL menerima daftar operator mutasi dengan informasi berikut tentang operator mutasi ROR: ROR 2 5 . MuEPL menggunakan informasi ini untuk menghasilkan mutan dari kueri EPL asli tersebut. Mengikuti Contoh 1 dan operator mutan ROR, komponen generator mutan MuEPL menghasilkan 5 kueri EPL mutan di mana operator relasional pertama akan digantikan oleh yang lain. Dalam Contoh 2, mutasi kueri Contoh 1 dapat ditemukan. Terakhir, komponen pelaksana MuEPL menjalankan mutan terhadap rangkaian pengujian yang akan dievaluasi, mengumpulkan kejadian yang dihasilkannya dalam setiap pengujian. Jadi, kasus pengujian adalah serangkaian kueri EPL yang disertakan dalam program asli yang dieksekusi menggunakan serangkaian kejadian masukan dan menghasilkan serangkaian kejadian keluaran; kejadian keluaran ini dibandingkan dengan kejadian yang dihasilkan oleh kueri EPL yang bermutasi dalam kondisi yang sama: mesin yang sama dan kejadian masukan yang sama.
| Operator | Atribut |
|---|---|
| 1 Penggantian operasi aritmatika (AOR) | +, *, −, / |
| 2 Penggantian operasi relasional (ROR) | <, >, =,! =, <=, >= |
Seperti yang disebutkan, pengujian mutasi telah diterapkan pada berbagai bahasa pemrograman. Bergantung pada bahasa pemrograman yang diuji mutasinya, format keluaran yang akan dianalisis bisa berbeda. Misalnya, jika bahasa pemrogramannya adalah C++, keluarannya bisa berupa angka, jika SQL adalah bahasa pemrograman yang diuji, keluarannya bisa berupa string. Dalam kasus kami, program EsperTech EPL mengeluarkan serangkaian kejadian.
Setelah menguji beberapa program Esper EPL dalam kondisi, mesin, dan input yang sama, penulis mendefinisikan mutan yang terbunuh sebagai mutan yang menghasilkan serangkaian peristiwa yang berbeda. Mengikuti definisi matematika yang umum tentang rangkaian, dua rangkaian peristiwa dianggap berbeda, ketika ada peristiwa dalam satu rangkaian yang tidak ada di rangkaian lainnya; urutan yang tepat tidak relevan. Pengujian yang gagal menunjukkan bahwa mutan terdeteksi dan, oleh karena itu, terbunuh. Definisi ini dipilih karena bahkan program Esper EPL yang sama dapat menghasilkan peristiwa dalam urutan yang berbeda di beberapa eksekusi. MuEPL mengimplementasikan definisi ini dengan terlebih dahulu membandingkan jumlah peristiwa yang diproses, dan kemudian memverifikasi bahwa peristiwa tersebut sama (meskipun dalam urutan yang berbeda). Oleh karena itu, ketika peristiwa keluaran serta jumlahnya sama, tidak peduli urutannya, kami menandai pengujian sebagai lulus.
Biaya tinggi pengujian mutasi perlu dikurangi, menggunakan teknik pengurangan biaya yang diteliti dengan baik untuk menghindari hasil yang bias. Domínguez-Jiménez et al. [ 3 ] menciptakan Evolutionary Mutation Testing ( EMT ), yang terdiri dari pembuatan sekumpulan mutan yang dikurangi dengan EA , yang mencari mutan yang berpotensi setara dan sulit dibunuh untuk membantu meningkatkan rangkaian pengujian. Pekerjaan saat ini mengevaluasi efektivitas EMT dan meningkatkannya dalam beberapa cara, menerapkannya pada kueri Esper EPL pada peristiwa dari sistem IoT.
2.3 Permainan
GAmera diperkenalkan oleh Domínguez-Jiménez et al. [ 9 ] sebagai alat pembangkit mutan pertama untuk menguji komposisi Layanan Web yang ditulis dalam bahasa WS-BPEL. GAmera dikembangkan dengan versi pertama EMT ; sebuah teknik optimasi untuk mengurangi jumlah mutan yang dihasilkan tanpa kehilangan efektivitas pengujian yang signifikan. EA digunakan untuk menghasilkan dan memilih subset mutan yang berpotensi setara dan sulit dibunuh. Pemilihan ini mengurangi biaya komputasi pengujian mutasi. Subset mutan yang dihasilkan dengan alat ini memungkinkan pengguna untuk meningkatkan kualitas rangkaian pengujian awal.
Teknik pengoptimalan EMT mungkin perlu direvisi berdasarkan bahasa yang diintegrasikan, atau lingkungan eksekusi. Hal ini dapat dilakukan berkat arsitektur berbasis komponen GAmera , di mana bagian-bagian algoritma dapat ditukar dengan implementasi lain. Teknik EMT serta EA akan dijelaskan dalam subbagian berikut.
2.4 Pengujian Mutasi Evolusioner
EMT menggunakan EA yang diimplementasikan oleh Domínguez-Jiménez et al. [ 9 ] untuk digunakan oleh alat GAmera untuk menghasilkan hanya sebagian kecil mutan, untuk mengurangi biaya. Algoritma ini bekerja dengan asumsi bahwa ada beberapa mutan dengan potensi lebih besar daripada yang lain untuk membantu penguji merancang kasus uji baru yang melengkapi yang sudah ada: mutan ini dikatakan kuat . Pembuatan mutan yang kuat disukai oleh pencarian EA , sehingga mengurangi jumlah mutan sambil mempertahankan kekuatan untuk menyempurnakan rangkaian pengujian. Ada dua jenis mutan yang kuat:
• Mutan yang berpotensi setara bertahan dalam rangkaian pengujian yang ada. Mutan ini perlu diperiksa untuk memeriksa apakah mutan tersebut setara dengan program asli. Jika tidak, mutan tersebut akan mengarah pada kasus pengujian baru, baik karena mutasi tidak tercapai, atau karena rangkaian pengujian tidak dapat membedakan mutan tersebut.
• Mutan yang sulit dibunuh dibunuh oleh kasus uji tertentu, yang tidak membunuh mutan lainnya. Bug yang sulit ditemukan dan sulit ditemukan dimodelkan dan berguna sebagai tempat yang harus difokuskan oleh algoritma.
2.4.1 Pengkodean Individu
Dalam EMT , mutan adalah individu untuk EA dan, dengan demikian, mereka harus diidentifikasi secara unik. Untuk tujuan ini, setiap mutan dikodekan dengan tiga bidang: operator (pengidentifikasi operator mutasi), lokasi (posisi di antara mutan operator tersebut) dan atribut (varian untuk disisipkan di suatu lokasi). Demi kejelasan, pertimbangkan informasi dalam Contoh 2 dan Tabel 1. Mutan diidentifikasi sebagai:
- Operator = 2: operator ROR diterapkan.
- Lokasi = 1: operator relasional pertama dalam kode dimutasi.
- Atribut = 1: operator relasional diubah ke varian pertama dalam set atribut yang telah ditentukan sebelumnya.
Contoh 2. Kueri asli dan yang telah diubah (> pertama diubah menjadi <). Pertanyaan asli: Pilih A sebagai temp1, B sebagai temp 2 dari pola [setiap temp1.temperature > 400 -> temp2.temperature > 400]
Kueri yang bermutasi:
Pilih A sebagai temp1, B sebagai temp 2 dari
pola [setiap temp1.temperature < 400 -> temp2.temperature > 400]
2.4.2 Langkah-langkah Utama
EA menghasilkan beberapa generasi mutan selama pelaksanaannya, diarahkan oleh pencarian mutan yang kuat melalui fungsi kebugaran. EA memulai dengan menghasilkan sekumpulan individu acak sebagai generasi pertamanya. Generator selanjutnya merupakan kombinasi dari berikut ini:
- Pembangkitan acak : parameter konfigurasi (persentase individu baru, N ) menentukan berapa banyak mutan yang akan dihasilkan secara acak. Mutan dihasilkan menurut distribusi seragam pada rentang bidang yang valid.
- Mutasi dan persilangan : individu baru lainnya dihasilkan dengan memodifikasi dan menggabungkan pasangan individu induk pada generasi sebelumnya. Induk dipilih melalui metode seleksi roulette yang dirancang oleh Goldberg [ 25 ], dengan probabilitas yang proporsional dengan kebugaran mereka. 3 Induk melalui satu atau dua proses ini secara acak, sesuai dengan probabilitas yang ditetapkan dalam konfigurasi:
- Mutasi : salah satu dari tiga bidang ( operator , lokasi atau atribut ) diganggu dengan menambahkan atau mengurangi sejumlah acak, sambil menghormati rentang nilai valid untuk bidang tersebut.
- Crossover : titik crossover acak dipilih antara bidang individu. Hal ini dapat mengakibatkan operator atau bidang atribut ditukar di antara individu. Dimulai dari dua induk ( operator 1 , lokasi 1 , atribut 1 ) dan ( operator 2 , lokasi 2 , atribut 2 ), salah satu titik crossover ini dipilih:
- Titik 1 ( operator ): menghasilkan ( operator 1 , lokasi 2 , atribut 2 ) dan ( operator 2 , lokasi 1 , atribut 1 ).
- Titik 2 ( atribut ): menghasilkan ( operator 1 , lokasi 1 , atribut 2 ) dan ( operator 2 , lokasi 2 , atribut 1 ).
Perlu dicatat bahwa nilai bidang dinormalisasi untuk memastikan setiap individu EA menunjuk ke mutan yang ada. Rincian lebih lanjut tentang hal-hal penting dari teknik dan overhead komputasinya disertakan dalam makalah oleh Domínguez-Jiménez et al. [ 3 ].
2.4.3 Fungsi Kebugaran
Algoritme tersebut mendukung pembuatan mutan yang kuat melalui desain fungsi kebugarannya. Kebugaran mutan menurun seiring dengan (i) bertambahnya jumlah kasus uji yang mendeteksi mutan, dan (ii) bertambahnya jumlah mutan yang dibunuh oleh kasus uji tersebut. Oleh karena itu, untuk menghitung fungsi kebugaran, setiap mutan harus dieksekusi terhadap setiap kasus uji.
Secara khusus, Persamaan 1 menunjukkan bagaimana kebugaran individu EA I dihitung sehubungan dengan rangkaian uji S. Algoritma menghasilkan matriks eksekusi m dengan ukuran M × T , di mana M adalah jumlah mutan, T adalah jumlah pengujian di S dan
adalah 1 atau 0 tergantung pada apakah mutan ke- i dibunuh oleh kasus uji ke- j atau tidak. Mutan yang gagal berlari sama sekali (yaitu, mutan yang lahir mati ) memiliki baris yang ditandai dengan nilai khusus 2, dan dibuang dari m . Setelah memperoleh m , kebugaran mutan didefinisikan sebagai:
![]()
Fungsi kebugaran menghitung kasus uji yang mendeteksi mutan, dan mutan yang dibunuh oleh kasus uji tersebut. Mutan dengan nilai tinggi untuk keduanya akan memiliki kebugaran rendah, karena mereka tidak memerlukan kasus uji yang sangat spesifik. Mutan yang berpotensi setara akan memiliki kebugaran maksimum, karena mereka belum dibunuh oleh kasus uji apa pun. Mutan yang sulit dibunuh akan memiliki nilai terbaik kedua karena mereka telah dibunuh hanya oleh satu kasus uji yang tidak membunuh mutan lainnya. Berkat nilai spesifik yang diberikan kepada mutan yang lahir mati, mereka dikecualikan sebelum EA diterapkan.
Salah satu fitur khusus EMT adalah fungsi kebugaran berevolusi seiring waktu karena didasarkan pada semua individu yang dihasilkan sejauh ini. Seiring dengan evolusi fungsi kebugaran, EMT mampu mendeteksi jenis mutan apa yang dapat dengan mudah dibunuh untuk kombinasi kasus uji dan rangkaian uji tertentu.
2.5 EMT Terpandu
Sebelum membahas sistem Tempus yang diusulkan , Guided EMT perlu dijelaskan. Gutiérrez-Madroñal et al. [ 11 ] menyajikan dua cara untuk mengeksekusi EMT : implementasi asli dan apa yang disebut Guided EMT . Pendekatan ini didasarkan pada karya Zhang et al. [ 10 ] yang memperkenalkan operator baru ( guided mutasi ) yang menghasilkan keturunan dengan menggabungkan informasi statistik global dan informasi lokasi solusi yang ditemukan sejauh ini. Setelah pengujian awal dengan implementasi ulang langsung dari guided mutasi, penulis menemukan bahwa pendekatan yang lebih sederhana berkinerja lebih baik untuk berbagai studi kasus. Operator mutasi Guided EMT berperilaku sebagai berikut:
- Pertama, Secara Acak Memilih Bidang yang Akan Dimutasi, Menggunakan Distribusi Seragam.
- Saat Mutasi Bidang Lokasi atau Atribut , Berfungsi Seperti Biasa.
- Ketika Operator Dimutasi , Akan Menghasilkan Angka x Antara 0 dan 1.
(A)
Jika x < α (di mana α adalah ‘laju pengambilan sampel’ dan merupakan parameter operator, yang saat ini ditetapkan ke 0,9), perilaku baru dipicu. Operator akan dipilih secara acak, di mana setiap operator memiliki probabilitas yang proporsional dengan rasio mutan kuat di antara mutannya yang telah dieksekusi sejauh ini.
Hal ini dirancang untuk memfokuskan perhatian pencarian (dengan probabilitas tertentu) ke fitur bahasa dalam program saat ini yang tampaknya belum diuji dengan baik, berdasarkan data yang tersedia saat ini. Misalnya, jika kita hanya menjalankan satu mutan dari operator tertentu, tetapi ini adalah mutan yang kuat, proses pencarian akan lebih mengutamakan mutan lain dari operator yang sama. Eksekusi mutan lain dari operator tersebut dapat menghasilkan mutan yang lebih kuat (mengkonfirmasi kecurigaan bahwa penguji tidak fokus pada area tersebut), atau dapat menghasilkan mutan yang terbunuh (membuatnya lebih mungkin bahwa pencarian akan beralih ke operator mutasi dengan rasio mutan kuat yang lebih tinggi).
(B)
Jika tidak, ia menggunakan gangguan acak seperti biasa.
2.6 Studi Kasus
Pada bagian ini, studi kasus yang digunakan sebagai rangkaian uji dalam MuEPL dan Guided EMT oleh Gutiérrez-Madroñal et al. [ 8 ] disajikan. Untuk menyederhanakan perbandingan dengan karya sebelumnya, makalah ini akan menggunakan studi kasus yang sama.
Kami memilih empat studi kasus dengan tujuan berbeda dan dari sumber berbeda: Ecological Island oleh Rosa-Gallardo et al. [ 26 ], Terminal Self-Service dari EsperTech [ 27 ], BruteForce oleh Gad [ 28 ] dan SnifferCongestion oleh Gad [ 23 ]. Perlu dicatat bahwa BruteForce dan SnifferCongestion adalah dua modul dari DENMEvaP , yang dibuat oleh Gad [ 28 ] (lihat Bagian 2.6.3 ). MuEPL membuat 181 mutan dari Ecological Island , 118 dari Terminal Self-Service , 286 dari BruteForce dan 61 dari SnifferCongestion . Singkatnya, kami bekerja dengan lebih dari 640 mutan dari 20 operator mutasi yang berbeda dari 34 yang didefinisikan untuk bahasa pemrograman Esper EPL. Untuk studi kasus yang dipertimbangkan, kami membedakan antara rangkaian pengujian asli dan yang diperluas dari masing-masing. Rangkaian uji yang diperluas telah dikembangkan secara khusus untuk memungkinkan identifikasi mutan yang ekuivalen dan tidak ekuivalen, serta untuk memfasilitasi perhitungan hubungan subsumsi antara mutan-mutannya 4 dengan mengikuti algoritma yang diusulkan oleh Papadakis et al. [ 29 ]. Penulis pertama secara manual memeriksa mutan-mutan hidup dari rangkaian uji terbesar di setiap studi kasus untuk memutuskan apakah mereka ekuivalen atau keras kepala, dan penulis kedua memeriksa silang temuan-temuan ini. Yao et al. [ 30 ] mendefinisikan mutan keras kepala sebagai mutan yang tidak terdeteksi oleh rangkaian uji berkualitas tinggi, namun tidak ekuivalen.
2.6.1 Pulau Ekologis
Program ini dilaksanakan di Universitas Cadiz oleh Rosa-Gallardo et al. [ 26 ]. Tujuannya adalah untuk mempromosikan pengembangan Kota Cerdas . Pulau-pulau ekologis dikaruniai ‘kecerdasan’ untuk mengurangi biaya bisnis, mengurangi polusi lingkungan dan meningkatkan efisiensi energi. Peristiwa yang terlibat adalah: deteksi kebakaran, input kontainer yang diblokir, kontainer setengah terisi dan kontainer terisi penuh. Ukuran program adalah 4 kueri EPL, dan memperoleh peristiwa JSON, rangkaian pengujian, dari lima saluran platform ThingSpeak [ 31 ]; setiap kasus pengujian berisi 100 peristiwa. Dari 4 kueri EPL, 181 mutan dihasilkan, yang 60 bertahan hidup (33%). Menghasilkan semua mutan dan mengeksekusi setiap mutan terhadap setiap kasus pengujian untuk menghasilkan matriks eksekusi penuh memakan waktu 378 menit (6 jam 18 menit). Kami mencoba untuk memperluas rangkaian pengujian untuk menghasilkan peristiwa JSON baru untuk membunuh mutan yang bertahan hidup, tetapi seperti yang ditunjukkan pada Tabel 2 , ini tidak memungkinkan. Ditemukan bahwa, di antara 60 mutan hidup, 27 mutan setara dan 33 mutan keras kepala. Kami mengamati bahwa mutan-mutan ini memengaruhi rentang waktu yang ditetapkan dalam kueri EPL, dan oleh karena itu, penggunaan file JSON sebagai input mencegah pembunuhan mereka.
| Operator | Setara | Keras kepala | Terbunuh | Total | Hidup/total |
|---|---|---|---|---|---|
| PRA | angka 0 | angka 0 | 4 | 4 | 0.00 |
| WTM | angka 0 | 4 | 4 | 8 | 0,50 |
| Bahasa Indonesia: TTL | angka 0 | 1 | 3 | 4 | 0,25 |
| RLO | angka 0 | angka 0 | 8 | 8 | 0.00 |
| RTU | angka 0 | 16 | angka 0 | 16 | 1.00 |
| RRO | 14 | angka 0 | 61 | 75 | 0.19 |
| Bahasa Indonesia: RNO | 5 | angka 0 | 41 | 46 | 0.11 |
| RSC | 8 | 12 | angka 0 | 20 | 1.00 |
| Total | 27 | 33 | 121 | 181 | 0.33 |
Rangkaian pengujian tidak mengidentifikasi mutan yang menggantikan: untuk setiap mutan, setidaknya ada satu mutan lain yang menghasilkan serangkaian hasil pengujian yang sama (terbunuh, tertutup, atau hidup). Secara total, ada 9 baris unik dalam matriks eksekusi di semua mutan yang terbunuh. Ini menunjukkan bahwa mutan di Pulau saling terkait erat: membunuh salah satu dari mereka kemungkinan akan membunuh yang lain.
2.6.2 Layanan Mandiri Terminal
Studi kasus ini membahas sistem pengelolaan terminal swalayan berbasis J2EE di bandara yang menerima sejumlah besar kejadian (sekitar 500 kejadian per detik) dari terminal yang terhubung. Beberapa kejadian menunjukkan situasi yang tidak normal dan yang lainnya menunjukkan aktivitas: check-in (pelanggan memulai dialog check-in), cancelled (pelanggan membatalkan dialog check-in), completion (pelanggan menyelesaikan dialog check-in), outoforder (terminal mendeteksi masalah perangkat keras) dan lowpaper (terminal kekurangan kertas).
Contoh ini, disediakan oleh EsperTech [ 7 ], menerima serangkaian peristiwa dari generator peristiwa terintegrasi. Peristiwa tersebut menyediakan informasi tentang terminal sumber. Setiap peristiwa membawa informasi serupa, yaitu, pengenal terminal dan stempel waktu. Ukuran program ini adalah 6 kueri EPL, dan total 120 mutan dapat dihasilkan, tidak ada yang setara. Seperti disebutkan di atas, studi kasus asli mengeksekusi peristiwa yang dihasilkan secara acak oleh generator peristiwa internalnya sendiri. Untuk memastikan konsistensi dan bahwa serangkaian peristiwa yang sama selalu dikelola, generator peristiwa asli digunakan untuk menghasilkan dua set berbeda yang terdiri dari 30 rangkaian pengujian, dengan masing-masing 5 kasus pengujian. Rangkaian pengujian asli ini membutuhkan waktu 19,6 menit untuk menghasilkan matriks eksekusi lengkap, dengan menghasilkan semua mutan dan menjalankan setiap mutan terhadap setiap kasus pengujian.
Untuk versi rangkaian uji yang diperluas, salah satu kasus uji dimodifikasi untuk membunuh mutan hidup yang tersisa. Modifikasi ini difasilitasi oleh kemungkinan untuk secara eksplisit memperkenalkan nilai-nilai pasti yang diketahui untuk membunuh mutan. Seperti yang ditunjukkan pada Tabel 3 , rangkaian uji yang baru berhasil membunuh semua mutan yang sebelumnya hidup. Rangkaian uji yang diperluas membutuhkan waktu 20,2 menit untuk menghasilkan matriks eksekusi yang lengkap.
| Operator | Setara | Keras kepala | Terbunuh | Total | Membunuh yang asli | Hidup asli / total |
|---|---|---|---|---|---|---|
| PNR | angka 0 | angka 0 | 2 | 2 | 2 | 0.00 |
| POM | angka 0 | angka 0 | 4 | 4 | 4 | 0.00 |
| PRA | angka 0 | angka 0 | 3 | 3 | angka 0 | 1.00 |
| POC | angka 0 | angka 0 | 3 | 3 | 1 | 0.67 |
| PFP | angka 0 | angka 0 | 3 | 3 | 3 | 0.00 |
| Bahasa Indonesia: WLM | angka 0 | angka 0 | 2 | 2 | 2 | 0.00 |
| Bahasa Inggris | angka 0 | angka 0 | 2 | 2 | 2 | 0.00 |
| Dunia Biru | angka 0 | angka 0 | 1 | 1 | 1 | 0.00 |
| Bahasa Indonesia: TTL | angka 0 | angka 0 | 1 | 1 | 1 | 0.00 |
| RLO | angka 0 | angka 0 | 4 | 4 | angka 0 | 1.00 |
| RTU | angka 0 | angka 0 | 20 | 20 | 20 | 0.00 |
| Bahasa Indonesia: RAO | angka 0 | angka 0 | 4 | 4 | 4 | 0.00 |
| RRO | angka 0 | angka 0 | 35 | 35 | angka 0 | 1.00 |
| Bahasa Indonesia: RNO | angka 0 | angka 0 | 2 | 2 | 2 | 0.00 |
| RGR | angka 0 | angka 0 | 2 | 2 | 2 | 0.00 |
| RSC | angka 0 | angka 0 | 30 | 30 | 30 | 0.00 |
| Bahasa Indonesia: IRC | angka 0 | angka 0 | 1 | 1 | 1 | 0.00 |
| Perusahaan | angka 0 | angka 0 | 1 | 1 | 1 | 0.00 |
| Total | angka 0 | angka 0 | 120 | 120 | 76 | 0.37 |
Rangkaian uji yang diperluas mengidentifikasi 4 mutan subsuming: 1 di WBL, 1 di RTU, 1 di RRO dan 1 di PNR. Namun, mutan subsuming ini tidak menggantikan mutan lain: mereka hanya memiliki baris unik dalam matriks eksekusi. Ada delapan baris bukan nol yang berbeda dalam matriks eksekusi yang dibagi oleh dua atau lebih mutan: dengan kata lain, mereka menghasilkan mutan duplikat , yang dibuang saat menghitung mutan subsuming seperti yang diusulkan oleh Papadakis [ 29 ].
2.6.3 BruteForce dan SnifferCongestion
DENMEvaP (Distributed Event-driven Network Monitoring Evaluation Prototype) sebuah program yang dibuat oleh Gad [ 28 ], berisi 37 kueri EPL yang memproses peristiwa dalam format PCAP (Packet CAPturer). Program ini dibagi menjadi lima modul yang memantau berbagai tugas. Dua dari modul ini adalah BruteForce, ukurannya adalah 6 kueri EPL dan SnifferCongestion, ukurannya adalah 4 kueri EPL. Modul BruteForce berisi 286 mutan. Jumlah total mutan untuk modul SnifferCongestion adalah 61.
Prototipe minimal terdiri atas jaringan dengan setidaknya dua komputer: simpul sensor bertindak sebagai penghasil kejadian dan memperoleh data mentah dalam jaringan komputer yang dipantau, dan simpul pemrosesan data menjadi tuan rumah infrastruktur komunikasi, mesin CEP, dan konsumen kejadian yang digunakan untuk mengukur hasil akhir.
Seperti yang dibahas, DENMEvaP dibagi menjadi beberapa modul dan untuk menguji perilaku masing-masing modul, serangkaian peristiwa PCAP dibuat. Awalnya, DENMEvaP memproses peristiwa PCAP secara langsung. Namun, untuk membunuh mutan yang membandel dan mempelajari hubungan subsumsi, DENMEvaP diperluas untuk menerima peristiwa dalam format JSON. Dengan mempertimbangkan hal ini, rangkaian pengujian terdiri dari dua rangkaian peristiwa: (i) file peristiwa PCAP asli yang tersedia di repositori penulis 5 —file PCAP untuk BruteForce berisi 6917 peristiwa (memerlukan 4188 menit atau 2,9 hari untuk menghasilkan matriks eksekusi lengkap), dan file PCAP untuk SnifferCongestion berisi 133 peristiwa (57 menit untuk menghasilkan matriks eksekusi lengkap)—dan (ii) serangkaian file peristiwa JSON yang baru dibuat, dibuat menggunakan alat IoT-TEG yang dikembangkan oleh Velez-Estevez et al. [ 32 ] satu untuk BruteForce yang berisi 18 peristiwa (membutuhkan 119 menit untuk menghasilkan matriks eksekusi lengkap), dan satu untuk SnifferCongestion yang berisi 12 peristiwa (membutuhkan 25 menit untuk menghasilkan matriks eksekusi lengkap).
Rangkaian pengujian yang diperluas untuk BruteForce mengidentifikasi 3 mutan yang menggantikan: 1 di PFP (mengganti 2 mutan), dan 2 di INC (mengganti 6 dan 0 mutan). Selain itu, ada 20 baris bukan nol yang berbeda dalam matriks eksekusi yang diduplikasi di dua atau lebih mutan. Pada Tabel 4 menunjukkan mutan yang dibunuh oleh rangkaian pengujian asli dan oleh rangkaian pengujian yang diperluas, yang memungkinkan pembedaan antara mutan yang setara dan tidak setara.
| Operator | Setara | Keras kepala | Terbunuh | Total | Membunuh yang asli | Hidup asli / total |
|---|---|---|---|---|---|---|
| PRA | angka 0 | angka 0 | 3 | 3 | 3 | 0.00 |
| POC | angka 0 | angka 0 | 3 | 3 | 3 | 0.00 |
| PFP | angka 0 | angka 0 | 3 | 3 | 3 | 0.00 |
| RLO | angka 0 | angka 0 | 7 | 7 | 7 | 0.00 |
| Angkatan Udara | angka 0 | angka 0 | 45 | 45 | 45 | 0.00 |
| Bahasa Indonesia: RAO | angka 0 | angka 0 | 4 | 4 | 4 | 0.00 |
| RRO | angka 0 | angka 0 | 165 | 165 | 163 | 0,01 |
| Bahasa Indonesia: RNO | angka 0 | angka 0 | 18 | 18 | 18 | 0.00 |
| RGR | angka 0 | angka 0 | 4 | 4 | 4 | 0.00 |
| RSC | angka 0 | angka 0 | 30 | 30 | 30 | 0.00 |
| Bahasa Indonesia: IRC | angka 0 | angka 0 | 2 | 2 | 2 | 0.00 |
| Perusahaan | angka 0 | angka 0 | 2 | 2 | 1 | 0,50 |
| Total | angka 0 | angka 0 | 286 | 286 | 283 | 0,01 |
Dalam kasus SnifferCongestion, terdapat 4 mutan yang disubsumsi: 2 dari IRC (masing-masing mengsubsumsi 2 dan 1 mutan), dan 2 dari RRO (tidak mengsubsumsi mutan lain). Terdapat 11 baris bukan nol yang berbeda dalam matriks eksekusi yang diduplikasi pada dua atau lebih mutan. Perbandingan mutan yang dibunuh oleh rangkaian uji asli dan rangkaian uji yang diperluas dapat dilihat pada Tabel 5 .
| Operator | Setara | Keras kepala | Terbunuh | Total | Membunuh yang asli | Hidup asli / total |
|---|---|---|---|---|---|---|
| PRA | angka 0 | angka 0 | 1 | 1 | 1 | 0.00 |
| POC | angka 0 | angka 0 | 1 | 1 | 1 | 0.00 |
| PFP | angka 0 | angka 0 | 1 | 1 | angka 0 | 1.00 |
| RLO | angka 0 | angka 0 | 1 | 1 | angka 0 | 1.00 |
| Bahasa Indonesia: RAO | angka 0 | angka 0 | 4 | 4 | 3 | 0,25 |
| RRO | angka 0 | 2 | 23 | 25 | 17 | 0.32 |
| Bahasa Indonesia: RNO | angka 0 | angka 0 | 2 | 2 | angka 0 | 1.00 |
| RSC | 8 | 12 | angka 0 | 20 | angka 0 | 1.00 |
| Bahasa Indonesia: IRC | angka 0 | angka 0 | 3 | 3 | 2 | 0.33 |
| Perusahaan | angka 0 | angka 0 | 3 | 3 | 3 | 0.00 |
| Total | 8 | 14 | 39 | 61 | 76 | 0.56 |
3 Waktu
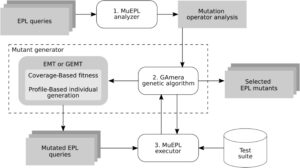
Tempus 6 adalah sistem yang menerapkan fungsi kebugaran Coverage-Aware baru dan pembuatan individu berbasis Profil baru ke kueri yang ditulis dalam Esper EPL. Fungsi kebugaran Coverage-Aware akan membantu mengetahui apakah eksekusi melewati bagian kueri tersebut. Peningkatan ini mempertimbangkan situasi tambahan: saat mutasi tercakup, tetapi hidup. Di sisi lain, peningkatan pembuatan individu berbasis Profil mencoba mengurangi biaya menemukan mutan kuat dengan menggunakan basis pengetahuan tentang distribusi mutan kuat per operator dalam program lain (yaitu, profil operator ini). Seperti disebutkan, tujuan penyempurnaan ini adalah untuk menghasilkan set mutan yang dikurangi menggunakan EA dari GAmera , yang mencari mutan kuat yang membantu meningkatkan rangkaian pengujian. Peningkatan ini akan dijelaskan di bawah, di Bagian 3.1 dan 3.2 .
Tempus menggabungkan MuEPL dan GAmera ke dalam proses terintegrasi dan menyediakan dua peningkatan yang disebutkan. Berkat implementasi GAmera, EMT dapat diterapkan ke bahasa pemrograman lain tanpa kompleksitas. Struktur GAmera telah digunakan untuk mengembangkan lebih banyak alat pengujian seperti Tempus atau Gigan Delgado-Pérez et al. (2017) Gambar 2 menguraikan proses yang diimplementasikan oleh Tempus . Tempus pertama-tama menggunakan komponen penganalisa MuEPL untuk mendapatkan daftar operator mutasi yang dapat diterapkan ke kueri EPL. Tempus kemudian menyediakan daftar tersebut ke algoritma EMT atau Guided EMT di GAmera (yang dapat dikonfigurasi untuk menggunakan fungsi kebugaran Coverage-Based baru atau pendekatan pembuatan individu Profile-Based) untuk mencari mutan yang kuat. Akhirnya, Tempus menyiapkan GAmera untuk menggunakan komponen pelaksana MuEPL untuk mengevaluasi apakah mutan itu kuat atau tidak, dengan menjalankannya terhadap rangkaian pengujian.
3.1 Informasi Cakupan
Yang et al. [ 33 ] mendefinisikan pengujian cakupan sebagai pengukuran proporsi perangkat lunak yang dijalankan dalam proses pengujian. Ada alat untuk mengukur cakupan pengujian untuk berbagai bahasa pemrograman, meskipun kami tidak dapat menemukan satu pun untuk kueri Esper EPL. Untuk mengukur cakupan, kami harus menginstrumentasikan mutan untuk mendeteksi apakah eksekusi melewati bagian kueri yang bermutasi, tanpa mengubah keluaran kueri. Setelah mempelajari EsperTech [ 34 ], ‘fungsi baris tunggal’ ditemukan sebagai jawabannya. Fungsi baris tunggal tidak memiliki status dan mengembalikan satu nilai: fungsi tersebut dapat muncul dalam ekspresi apa pun dan tidak mengubah keluaran. Tempus mengimplementasikan fungsi coveragePoint() yang, saat dijalankan, menyetel tanda tanpa memengaruhi keluaran kueri EPL. Contoh 3 menunjukkan bagaimana fungsi ini disertakan dalam kueri EPL untuk menginstrumentasikan mutan yang dihasilkan oleh operator ROR (awalnya ditampilkan dalam Contoh 2 ) di mana> diubah menjadi <, untuk mendeteksi apakah mutasi tercapai atau tidak. Penting untuk mengklarifikasi bahwa versi yang diinstrumentasikan dari operator mutasi yang mengukur cakupan menerapkan mutasinya dan memperkenalkan panggilan ke ‘fungsi baris tunggal’. Subbagian 3.1.1 menjelaskan bagaimana operator mutan yang sesuai untuk instrumentasi cakupan ini dipilih. Contoh 3. Fungsi baris tunggal dalam kueri yang bermutasi (> pertama diubah menjadi < ).
Kueri yang bermutasi dan diinstrumentasikan berdasarkan cakupan:
Pilih A sebagai temp1, B sebagai temp 2 dari
pola [setiap temp1.temperature < 400 coveragePoint()-> temp2.temperature > 400].
Ketika fungsi coveragePoint() dijalankan, sebuah tanda dipicu. Output kueri EPL tidak akan mengalami perubahan apa pun, tetapi MuEPL akan mengetahui bahwa kode yang bermutasi telah dijalankan dan ini akan tercermin dalam matriks eksekusi. Nilai fungsi kebugaran bergantung pada status mutan (hidup atau mati) dan apakah tanda dipicu. Perilaku fungsi kebugaran yang mengetahui cakupan dijelaskan dalam Subbagian 3.1.2 .
3.1.1 Mengukur Cakupan pada Operator Mutasi
Untuk mendeteksi mutan, eksekusi kasus uji harus (i) mencapai mutasi, (ii) menyebabkan perubahan dalam status internal, dan (iii) menyebarkan perubahan tersebut ke program yang sedang menjalani perilaku pengujian. Mutan dapat bertahan hidup karena pengujian tidak mencapai mutasi, atau karena pengujian tidak menunjukkan perilaku yang berbeda bahkan setelah mencapai mutasi. Untuk membedakan kedua skenario ini, kami menambahkan instrumentasi cakupan ke MuEPL sehingga dapat mendeteksi apakah eksekusi telah mencapai mutasi.
Kami memperhitungkan konstruksi kueri, serta jalur eksekusi saat memilih operator mutasi untuk menerapkan cakupan. Misalnya, jika operator mutasi muncul dalam klausa select atau dalam kata kunci where dari kueri, kami tahu bahwa eksekusi akan selalu melalui ini, jadi operator mutan tersebut tidak diinstrumentasikan. Selain itu, penelitian yang dilakukan oleh Tuya et al. [ 35 ] menunjukkan ada banyak mutan yang setara dalam klausa select . Selain itu, operator mutan yang mengubah jendela waktu dan panjang pola juga tidak diinstrumentasikan, karena ekspresinya selalu perlu dieksekusi untuk memfilter kejadian yang masuk.
Bahasa Indonesia: Dalam pekerjaan sebelumnya (Gutiérrez-Madroñal [ 24 ]), operator mutasi Esper EPL dibagi menjadi empat kategori 7 : operator ekspresi pola, operator jendela, operator penggantian dan operator serangan injeksi SQL. Karena pertimbangan di atas tentang beberapa bagian kueri yang selalu dieksekusi, instrumentasi cakupan tidak dipertimbangkan untuk operator ekspresi pola, operator jendela dan operator serangan injeksi SQL. Operator ini memengaruhi klausa select , windows dan klausa where secara berurutan. Ini hanya menyisakan 22 operator dalam kategori operator penggantian, yang mana RSC (Replacement Select Clause) juga dibuang karena hanya mengganti kata kunci dalam klausa select (dan klausa select selalu dijalankan). Singkatnya, ada 21 operator mutasi dalam kategori operator penggantian di mana instrumentasi cakupan dapat ditambahkan. 8 Operator mutasi ini mengganti nilai, kata kunci dan operator yang, ketika bagian kueri tersebut dieksekusi, lebih mungkin mengembalikan kesalahan.
3.1.2 Fungsi Kebugaran yang Mengetahui Cakupan
Dengan menggunakan instrumentasi cakupan, MuEPL dapat melaporkan situasi baru ke Tempus : ‘covered stubborn’. Seperti yang disebutkan sebelumnya, Yao et al. [ 30 ] mendefinisikan mutan stubborn sebagai mutan yang tidak terdeteksi oleh rangkaian uji berkualitas tinggi, namun tidak setara. Berdasarkan definisi oleh Yao et al. [ 30 ], mutan ‘covered stubborn’ adalah mutan stubborn yang terletak di bagian kueri EPL yang dieksekusi. Hal ini dikodekan dalam matriks eksekusinya sebagai
Fungsi kebugaran EMT dan EMT Terpandu , lihat Persamaan 2 , diubah untuk menggunakan informasi ini :
![]()
Dalam fungsi ini, k ( m , i ) didefinisikan sebagai 0 jika mutan ke-i dalam matriks eksekusi m tidak dibunuh oleh kasus uji apa pun, dan 1 jika mutan dibunuh oleh kasus uji. c ( x ) didefinisikan sebagai 0 jika x = 0 (mutan tidak tercakup oleh pengujian), 1 jika x = 1 (mutan tercakup dan dibunuh) dan sebagai 0,5 (tercakup keras kepala) jika x = 3. Akhirnya, v ( x ) didefinisikan sebagai 0 jika mutan masih hidup ( x = 0), 1 jika mutan dibunuh ( x = 1) dan Cf ( faktor cakupan ) jika mutan tercakup keras kepala ( x = 3).
C f harus ditetapkan ke angka dalam rentang (−1,+1), tergantung pada preferensi kita mengenai mutan keras kepala yang tercakup. Misalnya, jika preferensi kita adalah menganggap mutan keras kepala yang tercakup lebih dekat untuk dibunuh daripada mutan yang tidak tercakup, kita akan menetapkannya ke nilai positif (misalnya, 0,5), yang mengurangi kebugaran. Di sisi lain, jika kita menganggap mutan keras kepala yang tercakup lebih berharga daripada mutan yang tidak tercakup, kita akan menetapkannya ke nilai negatif (misalnya, -0,5).
3.2 Pembuatan Individu Berdasarkan Profil
Selain informasi cakupan, kami menyempurnakan pembuatan individu baru dalam EMT dan EMT Terpandu , untuk lebih jauh memandu penelusuran dengan menggunakan pengetahuan sebelumnya tentang operator mutasi khusus bahasa ( rasio mutan kuat program lain yang diketahui ).
Dari perspektif pencarian, sistem berbasis pengetahuan cenderung menggunakan pengetahuan domain untuk mengurangi ruang pencarian dan dengan cepat menemukan solusi yang tepat dengan sedikit eksplorasi. Sistem hibrida yang menggabungkan aspek terbaik dari keduanya (kecepatan dari sistem berbasis pengetahuan dan independensi domain dari EA ) akan lebih berguna untuk memecahkan masalah ini jika pengetahuan tersedia tetapi tidak cukup untuk mengatasinya secara optimal. Ide ini dimasukkan oleh Louis dan Zhao [ 36 ] untuk mengatasi masalah desain konfigurasi sistem: khususnya, desain struktural dan optimalisasi rangka.
Kami telah mengidentifikasi mutan yang kuat untuk setiap program studi kasus kami, yang dalam kasus ini bertepatan dengan mutan yang masih hidup. Tabel 2–5 menunjukkan bagaimana mutan yang masih hidup didistribusikan di antara operator untuk berbagai studi kasus.
Dengan membandingkan tabel-tabel tersebut, dapat dilihat bahwa RSC memiliki proporsi mutan hidup yang signifikan di Ecological Island dan Sniffer Congestion. Operator ini memodifikasi klausa select : seperti yang disebutkan dalam Subbagian 3.1.1 , penelitian oleh Tuya et al. [ 35 ] menyimpulkan bahwa sebagian besar mutan RSC yang bertahan hidup adalah ekuivalen. Demikian pula, program Island menunjukkan rasio mutan hidup yang tinggi untuk RTU. RTU mengganti satu unit waktu (milidetik, detik, menit, jam, atau hari) dengan yang lain dalam kelompok yang sama. Kami pikir mutan-mutan ini masih hidup karena kasus uji tidak cukup baik untuk membunuh mereka.
Profil kemungkinan umum bahwa mutan dari operator tertentu kuat dapat digunakan untuk memandu pencarian. Untuk menguji ide ini, kami bereksperimen dengan menjalankan Tempus untuk setiap program yang diteliti, sambil menggunakan basis pengetahuan tentang rasio mutan kuat yang diketahui per operator dari program lain yang diteliti.
menjadi jumlah mutan kuat untuk operator o dalam studi kasus ke- i , dan biarkan
menjadi jumlah total mutan dalam keadaan yang sama. Rasio mutan kuat yang ‘diketahui’ untuk operator o (‘profil yang diketahui’ dari o ) dapat didefinisikan seperti dalam Persamaan 3 , di mana i mencantumkan program lain (tidak termasuk program yang sedang diuji: misalnya, untuk Terminal akan mencantumkan Island, Sniffer, dan BruteForce):

| F | Operator | K0 | M0 | S0 | O0 | P | R0 |
|---|---|---|---|---|---|---|---|
| 1 | OP1 | 0.1 | 15 | 5 | 0.33̂ | 7 | 20.78 |
| OP2 | 0.2 | 10 | 5 | 0,50 | 7 | Tanggal 21.28 | |
| OP1 | 0.1 | 20 | 7 | 0.35 | 7 | 23.28 | |
| OP2 | 0.2 | 10 | 4 | 0.40 | 7 | Tanggal 20.28 | |
| 5 | OP1 | 0.1 | 15 | 5 | 0.33̂ | 12 | 40.83̂ |
| OP2 | 0.2 | 10 | 5 | 0,50 | 12 | 43.33̂ | |
| OP1 | 0.1 | 20 | 7 | 0.35 | 12 | 53.33̂ | |
| OP2 | 0.2 | 10 | 4 | 0.40 | 12 | Nomor telepon 38. |

4 Desain Percobaan
Bagian ini menyajikan evaluasi efektivitas penyempurnaan yang diusulkan (kebugaran yang memperhatikan cakupan, dan profil operator) untuk kueri Esper EPL, baik menggunakan EMT maupun EMT Terpandu . Subbagian berikut akan membahas pertanyaan penelitian dan proses eksperimen. Tujuan evaluasi ini juga untuk menilai bagaimana EMT dapat membantu meningkatkan rangkaian uji asli dengan mengidentifikasi mutan yang masih belum terbunuh.
4.1 Pertanyaan Penelitian
Seperti yang disebutkan, usulan perbaikan EMT bertujuan untuk memandu pencarian dengan sumber informasi baru. Hal ini menimbulkan pertanyaan penelitian berikut:
RQ1: Operator mutasi mana yang dapat menginstrumentasikan kueri EPL untuk mengukur cakupan mutasi pada lingkungan eksekusi yang tidak dimodifikasi? Di antara operator tersebut, mana yang lebih sering menghasilkan mutan keras kepala yang tercakup?
RQ2: Dapatkah fungsi kebugaran yang mengetahui cakupan mengurangi biaya komputasi dalam menemukan mutan yang kuat?
RQ3: Dapatkah pengetahuan sebelumnya mengenai operator mutasi mengurangi biaya komputasi dalam menemukan mutan yang kuat?
4.2 Proses Eksperimen
Setelah mendefinisikan pertanyaan penelitian, tugas selanjutnya adalah mengumpulkan data untuk menjawabnya. RQ1 memerlukan analisis kueri Esper EPL yang terlibat dalam studi kasus, dan mempelajari mutan mana yang tidak dapat dieksekusi. Ini akan membantu kita menentukan operator mutasi mana yang dapat diperluas untuk mengukur cakupan. Untuk menjawab RQ2 dan RQ3, langkah-langkah berikut diikuti untuk setiap studi kasus:
1.
Jalankan semua mutan untuk mengetahui berapa banyak yang kuat dengan rangkaian pengujian saat ini. Eksekusi sebelumnya ini akan digunakan sebagai dasar kebenaran untuk menghitung hasil kami.
2.
Jalankan EMT dan EMT Terpandu dengan fungsi kebugaran Coverage-Aware sambil menghukum mutan yang tercakup tetapi masih hidup (mengatur faktor cakupan ke -0,5), berhenti saat kami menemukan S % mutan yang kuat . Kemudian, ukur berapa banyak mutan yang harus dijalankan. Idealnya, kami ingin berhenti sebelum menjalankan S % dari semua mutan: semakin sedikit, semakin baik. Kami menggunakan 30 kali uji coba dengan benih acak yang berbeda untuk mengevaluasi stabilitas algoritme di seluruh benih.
EMT adalah algoritma kompleks dengan banyak parameter berbeda. Studi ini menggunakan nilai-nilai yang direkomendasikan oleh Domínguez-Jiménez et al. [ 3 ] dalam studi pertama tentang EMT , yang tercantum dalam Tabel 7. Ukuran populasi adalah berapa banyak mutan yang akan diproduksi di setiap generasi dan merupakan rasio dari jumlah total mutan untuk setiap aplikasi. Untuk setiap generasi, proporsi individu tertentu baru dihasilkan. Sisanya dihasilkan oleh crossover/mutasi populasi sebelumnya: jumlah probabilitasnya selalu 100%.
3.
Ulangi langkah di atas untuk EMT dan EMT Terpandu dengan fungsi kebugaran Coverage-Aware, kali ini mengutamakan mutan yang ‘tertutup tetapi hidup’ (mengatur faktor cakupan menjadi + 0,5), dengan benih dan rangkaian pengujian yang sama.
4.
Ulangi langkah pertama untuk EMT dan EMT Terpandu , menggunakan profil operator dengan F ( faktor imbalan ) ditetapkan ke 1 dan benih serta rangkaian pengujian yang sama.
5.
Ulangi langkah di atas untuk EMT dan EMT Terpandu , menggunakan profil operator dengan F = 5 dan benih serta rangkaian pengujian yang sama.
| Parameter | Nilai |
|---|---|
| Ukuran populasi | 5% |
| Individu yang dihasilkan secara acak | 10% |
| Probabilitas crossover | 70% |
| Kemungkinan mutasi | 30% |
Untuk menjawab RQ2 dan RQ3, kita perlu membandingkan hasil EMT dengan penyertaan informasi cakupan dan fungsi kebugaran generasi individu berbasis Profil, terhadap EMT , EMT terpandu , dan pemilihan acak. Jika salah satu modifikasi EMT yang disebutkan mengurangi biaya, maka akan ditemukan persentase target mutan yang kuat. lebih cepat.
Sebuah penelitian oleh Guizzo et al. [ 37 ] menemukan bahwa jumlah mutan merupakan ukuran yang tidak akurat dari biaya komputasi yang sebenarnya dan bahwa waktu eksekusi harus digunakan sebagai gantinya. Dengan mempertimbangkan penelitian ini, waktu eksekusi yang dibutuhkan oleh setiap algoritma untuk menemukan mutan yang kuat S% diukur. 9 Ini akan menjelaskan ketidakakuratan yang melekat pada jumlah mutan.
5 Hasil
Subbagian berikut menyajikan hasil untuk pertanyaan penelitian kami. 10 Untuk RQ1, kami menunjukkan operator mutasi Esper EPL mana yang sesuai untuk perluasan cakupan. Untuk RQ2 dan RQ3, kami menunjukkan usulan perbaikan yang menghasilkan hasil yang lebih baik.
5.1 RQ1
Seperti disebutkan dalam Bagian 3.1 , hanya beberapa operator mutasi Esper EPL yang dapat dianalisis cakupannya: 21 operator mutasi dalam kategori mutasi pengganti. Kita perlu memeriksa operator mana yang dapat diterapkan ke semua program dari studi kasus kita. Selain itu, kita ingin mengetahui operator mana yang tercakup dan menghasilkan mutan yang masih hidup, mutan keras kepala yang tercakup.
Dalam studi kasus yang dipilih, di antara 21 operator tersebut, dimungkinkan untuk menerapkan RAF, RAO, RGR, RLO, RNO, RRO, dan RTU. Dengan memilih yang menghasilkan mutan hidup dan dapat diterapkan pada keempat studi kasus, kumpulan kandidat dikurangi menjadi tiga: RLO, RRO, dan RNO. Tabel 8 menunjukkan mutan total, ekuivalen, dan bandel menurut program dan operator. Tabel 9 menunjukkan mutan bandel yang tercakup dari setiap operator di setiap program, untuk rangkaian uji asli dan rangkaian uji yang diperluas jika ada.
| Operasi. | RLO | Bahasa Indonesia: RNO | RRO | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | Bahasa Inggris | S | S asli | T | Bahasa Inggris | S | S asli | T | Bahasa Inggris | S | S asli | |
| Terminal | 4 | angka 0 | angka 0 | 4 | 2 | angka 0 | angka 0 | angka 0 | 35 | angka 0 | angka 0 | 4 |
| Kekuatan kasar | 7 | angka 0 | angka 0 | angka 0 | 18 | angka 0 | angka 0 | angka 0 | 165 | angka 0 | angka 0 | angka 0 |
| Sinf. kemacetan | 1 | angka 0 | angka 0 | 1 | 2 | angka 0 | angka 0 | 2 | 25 | angka 0 | 2 | 1 |
| Pulau Ekologi | 8 | angka 0 | angka 0 | 46 | 5 | angka 0 | 75 | 14 | angka 0 | |||
| Total | 20 | angka 0 | angka 0 | 5 | 68 | 5 | angka 0 | 2 | 300 | 14 | 2 | 5 |
| Operasi. | RLO | Bahasa Indonesia: RNO | RRO | |||
|---|---|---|---|---|---|---|
| Status | Bahasa Inggris | CS asli | Bahasa Inggris | CS asli | Bahasa Inggris | CS asli |
| Terminal | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 |
| Kekuatan kasar | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | 2 |
| Sinf. kemacetan | angka 0 | 1 | angka 0 | 2 | 2 | 8 |
| Pulau Ekologi | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 |
| Total | angka 0 | 1 | angka 0 | 2 | 2 | 10 |
Meskipun mutan RLO, RRO, dan RNO muncul di semua program, informasi cakupan hanya bermakna dalam dua dari empat studi kasus (BruteForce dan SnifferCongestion). Di Terminal, semua mutan RRO dan RLO dibunuh oleh rangkaian uji yang diperluas, tetapi rangkaian uji asli tidak mencakupnya. Dua mutan RNO di Terminal muncul dalam klausa select , yang selalu dieksekusi, jadi tidak perlu mengukur cakupan (lihat Contoh 4 ). Untuk program Island, ada 14 mutan hidup RRO dan 1 RNO yang dicakup oleh rangkaian uji, tetapi semuanya setara.
Contoh 4. Mutasi RNO di Terminal.
//pertanyaan EPL asli
Pilih ‘1’ sebagai terminal, … dari pola …
//Mutan RNO pertama
Pilih ‘0’ sebagai terminal, … dari pola …
//Mutan RNO kedua
Pilih ‘2’ sebagai terminal, … dari pola …
BruteForce memiliki sembilan mutan keras kepala yang tertutup untuk RRO dalam rangkaian pengujian asli. SnifferCongestion memiliki 11 mutan keras kepala yang tertutup di antara tiga operator dalam rangkaian pengujian aslinya: rangkaian yang diperluas membunuh sebagian besar dari mereka, hanya menyisakan dua mutan keras kepala untuk RRO.
Jawaban untuk RQ1 adalah bahwa operator mutasi yang dapat diinstrumentasikan dengan analisis cakupan adalah 21 yang dijelaskan di Bagian 3.1.1 . Ada 34 operator mutasi Esper EPL, yang diklasifikasikan ke dalam empat kategori tergantung pada jenis elemen sintaksis yang terkait dengannya. Kami tidak menginstrumentasikan operator mutasi yang mutasinya akan selalu dijalankan, seperti yang diterapkan pada klausa select , kata kunci where , atau jendela waktu dan panjang. Kami selanjutnya mengurangi operator yang memerlukan instrumentasi dengan hanya mempertimbangkan yang dapat diterapkan pada studi kasus, dan yang menghasilkan mutan hidup: RLO, RNO, dan RRO. Ketiganya menghasilkan mutan keras kepala yang tercakup untuk rangkaian uji asli di SnifferCongestion. RRO menghasilkan mutan keras kepala yang tercakup untuk rangkaian uji asli dan yang diperluas dari SnifferCongestion, dan untuk rangkaian uji asli BruteForce.
5.2 RQ2 dan RQ3
Dalam kedua pertanyaan penelitian, kami ingin menentukan apakah penyempurnaan yang diusulkan mengurangi biaya komputasional pengujian mutasi. Proses yang sama dilakukan untuk setiap penyempurnaan. Setiap studi kasus dipelajari dengan memeriksa apakah kita dapat mencapai mutan kuat yang diinginkan lebih cepat dengan lebih menyukai atau menghukum ‘mutan yang tercakup tetapi hidup’ atau dengan mempertimbangkan profil operator, dalam konteks EMT dan EMT Terpandu . Berkat eksekusi semua mutan sebelumnya, kita tahu berapa banyak yang kuat dengan rangkaian pengujian saat ini (digunakan sebagai kebenaran dasar untuk menghitung hasil kita). Di bagian ini, kita akan memeriksa apakah teknik-teknik tersebut memiliki perbedaan yang signifikan secara statistik dalam biaya komputasional yang diperlukan untuk menemukan proporsi mutan yang kuat tertentu, dan apakah teknik-teknik tertentu secara konsisten lebih baik daripada yang lain.
5.2.1 Menetapkan Signifikansi Statistik Perbedaan Waktu Eksekusi
Pertama, untuk masing-masing dari 4 studi kasus, waktu pelaksanaan dari 11 teknik berbeda untuk menemukan 5 proporsi target mutan kuat yang berbeda ( S %∈{30%,45%,60%,75%,90%}) di 30 benih acak yang berbeda dikumpulkan. Ini berarti setiap teknik dieksekusi 150 kali. Teknik-teknik tersebut adalah: EMT (EMT), Guided EMT (GEMT), faktor cakupan positif dengan EMT (EMTCPlus) dan Guided EMT (GEMTCPlus), faktor cakupan negatif dengan EMT (EMTCMinus) dan Guided EMT (GEMTCMinus), PBig individu baru menggunakan faktor hadiah = 1 dengan EMT (EMTP) dan Guided EMT (GEMTP), PBig individu baru menggunakan faktor hadiah = 5 dengan EMT (EMTP5) dan Guided EMT (GEMTP5) dan pemilihan acak (Random).
Karena waktu eksekusi di atas tidak terdistribusi normal, uji non-parametrik dipilih untuk mengevaluasi apakah perbedaan waktu eksekusi teknik-teknik tersebut signifikan secara statistik: uji Friedman [ 38 ], dengan ambang signifikansi α = 0,05. Perhatikan bahwa uji Friedman didasarkan pada pemeringkatan teknik untuk setiap pasangan (seed, S %), jadi perbedaan dalam besaran waktu eksekusi saat S % menjadi lebih tinggi tidak memengaruhi pengujian. Hipotesis nol untuk uji Friedman adalah bahwa waktu eksekusi untuk berbagai teknik berasal dari populasi yang sama (yaitu, bahwa teknik-teknik tersebut tidak berbeda secara signifikan satu sama lain dalam biaya komputasi), dan hipotesis alternatifnya adalah bahwa setidaknya ada dua teknik yang berbeda satu sama lain. Nilai – p di keempat kasus uji lebih rendah dari α (seperti yang ditunjukkan pada Tabel 10 ), yang menunjukkan ada teknik-teknik yang berbeda secara signifikan satu sama lain dalam biaya komputasi.
| Studi kasus | P | Kendall W |
|---|---|---|
| Kekuatan Kasar | 1.07e-141 | 0.46 |
| Pulau | 5.09e-120 | 0.39 |
| SnifferKemacetan | 4.53e-117 | 0.38 |
| Terminal | 5.55e-227 | 0.72 |
Sebagai ukuran ukuran efek, nilai untuk koefisien konkordansi Kendall W dihitung untuk setiap studi kasus (juga ditunjukkan dalam Tabel 10 ). Kendall W adalah estimasi varians jumlah baris peringkat dibagi dengan nilai maksimum yang mungkin diambil varians tersebut [ 35 ], 11 dan berkisar dari W = 0 (tidak ada kesepakatan antara juri) dan W = 1 (kesepakatan sempurna antara juri, yaitu, teknik selalu diberi peringkat yang sama di semua eksekusi). Dapat disimpulkan bahwa urutan relatif teknik sangat konsisten di Terminal, kurang konsisten di BruteForce dan paling tidak konsisten di Island dan SnifferCongestion.
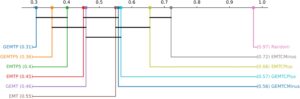
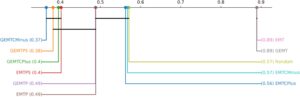
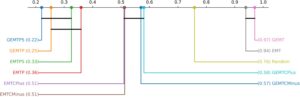
5.2.2 Perbandingan Teknik
Bahasa Indonesia: Setelah menetapkan dengan uji Friedman bahwa ada teknik yang secara signifikan berbeda satu sama lain dalam setiap studi kasus, langkah berikutnya adalah mencari tahu bagaimana teknik tersebut dibandingkan satu sama lain. Mengikuti prosedur yang direkomendasikan oleh [ 40 ], uji Nemenyi post hoc digunakan untuk membandingkan setiap pasangan teknik dalam setiap studi kasus (dengan α = 0,05). Hasilnya disajikan dalam diagram perbedaan kritis pada Gambar 7 – 10 . Diagram perbedaan kritis memplot setiap teknik pada sumbu horizontal, berdasarkan peringkat persentil rata-rata mereka dalam waktu eksekusi di 150 pasangan proporsi benih dan target mutan yang kuat (semakin rendah semakin baik). Crossbars menghubungkan klik maksimal teknik yang tidak memiliki perbedaan yang signifikan secara statistik antara satu sama lain.